

| Daniel Pecos Martínez | Alfredo Prades González | David Díez Muñoz |
| al024479@alumail.uji.es | al025241@alumail.uji.es | al027996@alumail.uji.es |

1º INGENIERÍA INFORMATICA
U.J.I. CURSO 1999/2000
RESUMEN
En este trabajo comentamos diversos campos relacionados con Linux, pasando por el kernel, el sistema X Window, el shell y, por supuesto, la red, característica por la cual Linux ha tenido este auge durante los últimos años.
INDICE
-
1.1 GNU
1.3 LILO
-
2.1.1 Estructura del Sistema
2.1.2 Procesos y Tareas
2.2 PRINCIPALES ESTRUCTURAS DE DATOS
2.2.1 Estructura de Tarea
2.2.2 La Tabla de Procesos
2.2.3 Ficheros y inodes
2.3 PRINCIPALES MECANISMOS DEL KERNEL
2.3.1 Señales
2.3.2 Tuberías
2.3.3 Interrupciones
2.3.4 Iniciando el sistema
2.3.5 Interrupción del Reloj
2.4 EL SISTEMA DE ARCHIVOS DE LINUX
2.4.1 Conocimientos básicos
2.4.2 El Virtual File System
2.4.3 Sistema de Ficheros Ext2
2.4.4 Sistema de Ficheros Proc
-
4.1 ¿QUÉ ES UNA RED DE COMPUTADORES?
4.2 REDES UUCP
4.2.1 Funcionamiento de UUCP
4.3 REDES TCP/IP
4.3.1 TCP/IP frente a UUCP
4.3.2 Introsucción a las redes TCP/IP
4.4 HARDWARE
4.4.1 Ethernets
4.4.2 Otros tipos de Hardware
4.5 PROTOCOLOS
4.5.1 El protocolo IP (Internet Protocol)
4.5.2 IP en líneas serie, SLIP
4.5.3 El Protocolo de Control de Transmisiones, TCP
4.5.4 Protocolo de Mensajes de Control de Internet (ICMP)
4.6 HISTORIA DE LAS REDES CON LINUX
4.8.1 Resolución de nombres
4.8.2 Introducción al DNS
-
5.3 ARQUITECTURA CLIENTE/SEVIDOR
5.4 XFRee86
5.5 EL ARRAANQUE DEL SISTEMA X-WINDOW
5.6.1 Fvwm y sus derivados
1 INTRODUCCIÓN
Linux es un sistema operativo libre de características muy semejantes a UNIX. Originalmente fue desarrollado para PC, aunque hoy en día Linux es capaz de correr en distintas plataformas.
Linux es compatible con el estándar POSIX 1003.1 e incluye gran cantidad de funciones de UNIX y BSD. Gran parte del código del kernel ha sido escrito por Linus Torvalds, que fue quien comenzó el desarrollo de Linux, usando la licencia GNU para las fuentes del sistema.
Sin duda alguna ha sido Internet, junto a la licencia GNU, lo que ha dado este impulso al sistema operativo Linux, ya que desde un primer momento las fuentes estuvieron disponibles para todo aquel que quisiera sin tener que pagar nada, haciendo así posible personalizar el sistema operativo para cada uno, desarrollando drivers propios. Esta característica hizo que el desrrollo de Linux se realizase a nivel mundial, siendo el coordinador del proyecto Linus Torvalds.
1.1 GNU
La licencia general pública GNU (del acrónimo recursivo GNU’s Not Unix) es con la que está registrada la mayoría del software de las distrubuciones linux . Aunque solo la distribucion Debian esta totalmente bajo la licencia general pública GNU, la mayoría del software de las otras distribuciones esta englobado en la licencia GNU. Richard Stallman fue quien puso las bases de esta idea. En 1983 Richard Stallman escribio el anuncio del proyecto GNU que empezba diciendo: UNIX Libre!
El proyecto venia a decir que se necesitaba gente y máquinas para desarrollar un sistema totalmente compatible con Unix que fuera completamente gratuito. Este sistema tenia algunas mejoras repecto a su sistema en el que se basa linux. Esta licencia es la que ha permitido que linux se desarrolle por todo el mundo a la vez y se pueda desarrollar un programa a traves de todo el mundo.
La licencia dicta que todo los programas que se distribuyan lo han de hacer con su código fuente permitiendo que cualquiera lo pueda modificar y registrarlo con la misma licencia para distribuirlo libremente, si pone el nombre del autor original y la propia licencia al distribuirlo.
Otro punto interesante de la licencia es que si alguien cobra dinero al vender un programa bajo esta licencia no puede impedir a quien lo compre que lo distribuya libremente. Ahora ofrecemos la posibilidad de visitar páginas relacionadas con este tema:
- Licencia general pública GNU.
- Página general de GNU.
- Página de compañeros donde se puede encontrar la licencia GNU traducida al catalán.
1.2 CARACTERÍSTICAS GENERALES
Linux cumple con todos los requisitos que se le puede pedir a un sistema UNIX:
- Multi-TareaTodos los procesos en ejcución corren independientemente unos de otros.
- Acceseo multi-usuarioLinux permite el acceso simultáneo de diferentes usuarios al mismo ordenador.
- Multi-procesadorDesde la version 2.0 del núcleo, Linux soporta múltiples procesadores, distribuyendo las tareas en distintos procesadores.
- Independencia de arquitecturaExisten distintas versiones de Linux para distintas arquitecturas, desde Amiga hasta PC, pasando por DEC Alpha y Macs. Esta característica es exclusiva de Linux, de momento.
- PagingA pesar del esfuerzo para la optimización del uso de la memoria, puede ocurrir que el sistema se quede sin esta. Cuande esto ocurre, Linux busca páginas de memoria de 4Kb que puedan ser liberadas (las páginas cuyo contenido ya esté almacenado en disco son descartadas). Una vez se han seleccionado son copiadas al disco, liberando así, memoria. Si éstas fueran a ser necesitadas de nuevo, se recargan a la memoria. Este procedimiento difiere del swapping en que no se vuelca toda la memoria usada por un proceso, lo cual es menos eficiente.
- Librerías compartidasLas librerías contiene rutinas usadas por distintos procesos, los cuales al ser lanzados, no vuelven a cargar estas librerías si ya han sido cargadas por algún otro proceso, aprovechando así mejor la memoria.
- Diferentes sistemas de ficherosLinux es capaz de soportar distintos sistemas de ficheros, como pueden ser: FAT 16, FAT 32, ISO, HPFS, etc, y, por supuesto el suyo propio Ext2.
1.3 LILO
El LInux LOader es el encargado de cargar el sistema operativo.Ademas es capaz de cargar distintos sistemas operativos como Windows y Windows NT. Se suele instalar en el MBR, desde donde se ejecuta cada vez que se inicia el sistema.
Existe un programa llamado Loadlin que es capaz de carga linux desde DOS con solo tener una copia del kernel, con lo cual es más fácil acceder a Linux desde este sistema opertativo (este procedimiento es el que suele usarse para lanzar Linux en las distribuciones llamadas habitualmente como WinLinux).
En la última versión es capaz de lanzar sistemas operativos que se encuentren en particiones más allá del cilindro 1024, cosa que hasta ahora no era capaz de hacer y era uno de sus mayores inconvenientes.
2 EL KERNEL
2.1 ¿QUÉ ES EL KERNEL?
El kernel es el sistema central de cualquier sistema operativo. Todos los sistemas operativos constan de una parte encargada de gestionar los diferentes procesos y las posibles comunicaciones entre el hardware de un ordenador con los programas que están en funcionamiento, entre otras y variadas tareas. Es, por ejemplo, el que facilita el acceso a datos en los distintos soportes posibles (CD-ROM, unidad de disco duro, unidad ZIP, etc.), o el que arranca el ordenador, o el que resetea todos los dispositivos que sean necesarios.
La principal propiedad de un kernel es que todas estas operaciones de manejo de memoria o de dispositivos, son, desde un punto de vista de usuario, totalmente transparentes, esto es, no es necesario saber como trabajar a bajo nivel con el procesador para realizar las operaciones que sean necesarias, ya que será el kernel, a través de una serie de instrucciones ya implementadas el que lo hará por nosotros.
Para todo aquel que llegado este punto desee continuar con la lectura de este apartado, quiero advertirle que si está buscando una ayuda rápida de nivel medio-avanzado, no espere encontrarla en esta web. Aquí únicamente trato las diferentes partes de que consta el kernel y su funcionamiento, pero no el uso del sistema operativo. Para el que esté interesado en este tema le recomiendo conseguir el libro [MP98], el cual es una introducción a este gran sistema operativo para un usuario no iniciado en él.
2.1.1 Estructura del sistema
Los kernels de Windows NT o Minix son de tipo micro-kernel, caracterizado porque proveen al sistema de un estado mínimo necesario de funcionalidad, cargando el resto de funciones necesarias en procesos autónomos e independientes unos de otros, comunicándose con este micro-kernel a través de una interfaz bien definida. Este tipo de estructura es más fácil de mantener y el desarrollo de nuevos componentes es mucho más simple, dando a su vez una mayor estabilidad al sistema. Por otro lado, debido a la estructura rígida del interfaz, estos tipos de kernel son mucho más complicados de reestructurar, y además, debido a las arquitecturas del hardware actual, el proceso de intercomunicación dentro del micro-kernel es mucho más que una simple llamada, por lo que hace que esta estructura sea más lenta que los kernels de tipo monolíticos o macro-kernels.
No hay que olvidar que Linux ha sido desarrollado como un simple placer por desarrollar un sistema, el cual ha evolucionado gracias a diferentes programadores de todo el mundo. Debido a esto, una estructura de micro-kernel es prácticamente inconcebible, aunque esto no quiere decir que el kernel de linux sea una simple lista de instrucciones sin estructura alguna. A pesar de la estructura de macro-kernel, se ha intentado equiparar su velocidad utilizando código optimizado en velocidad (aunque complicado de entender), y se ha recuperado algunas de las mejores características de la estructura de micro-kernel, como puede ser la carga de los diferentes drivers necesarios como módulos independientes, siempre sin olvidar la estructura monolítica original.
En el caso de Linux, la gran parte del kernel está escrito en C, existiendo también instrucciones en ensamblador, aunque estas ultimas se usan mayoritariamente en los procesos de arranque y en el control de co-procesador. A continuación se muestra una tabla con la cantidad de lineas en C y ensamblador que se usan aproximadamente en la versión 2.0 del kernel de Linux, el cual consta de unas 470.000 lineas de código (la versión 1.0 constaba “únicamente” de 165.000 lineas):
| Módulo | Código C | Ensamblador |
|---|---|---|
| Dispositivos de Drivers | 377.000 | 100 |
| Network | 25.000 | |
| VFS | 13.500 | |
| 13 archivos de sistema | 50.000 | |
| Inicio | 4.000 | 2.800 |
| Co-Procesador | 3.550 |
Tabla 1 – Proporciones de código fuente por componente
A modo de curiosidad cabe comentar el significado de la serie de números que acompañan al kernel, tanto compilado como al directorio que contiene las fuentes de éste, que, a pesar de no ser necesarios, se suelen incluir porque aportan una mayor información. Este conjunto de cifras tienen el formato X.X.XX y su significado no es más que la versión del kernel a la que corresponde dicho archivo, aunque no es simplemente así. Como se puede suponer, la variación en una unidad del primer grupo de cifras significa un cambio muy importante en el kernel, siendo ésta menor conforme el grupo de cifras que varía está más hacia la derecha. El último grupo de cifras tiene, además del significado anterior como indicador de versión, un significado añadido, que es el de que si la cifra es par, esa versión de kernel se considera como una versión estable, si, en cambio ésta es impar, se considera que la versión del kernel es una versión en fase beta o de desarrollo.
2.1.2 Procesos y Tareas
Desde el punto de vista de un proceso ejecutándose en Linux, el kernel es un proveedor de servicios. Cada proceso existe por separado y el espacio de memoria reservado a cada uno de ellos está protegido para que no pueda ser modificado. Desde este punto de vista, se está llevando a cabo un sistema multiproceso real (ver Figura 1).
Desde un punto de vista interno, la cosa es distinta. Solo hay un proceso en marcha en el ordenador que puede acceder a todos los recursos, el sistema operativo. El resto de tareas se llevarán a cabo como co-rutinas, las cuales, de una forma totalmente independiente, deciden por ellas mismas a qué tarea y cuándo pasarán el control. Debido a esto, un fallo en la programación del kernel podría bloquear todo el sistema.
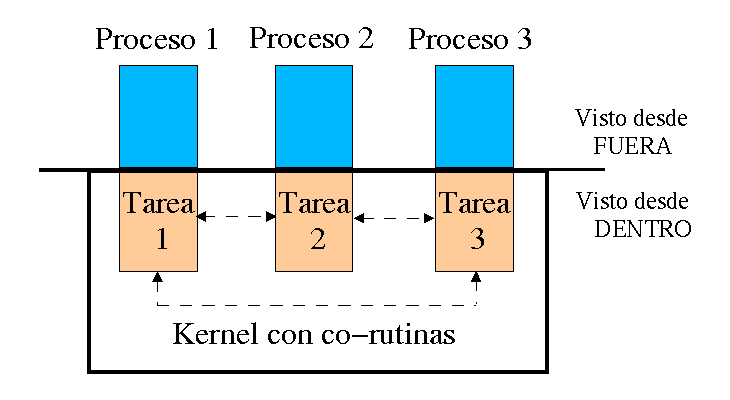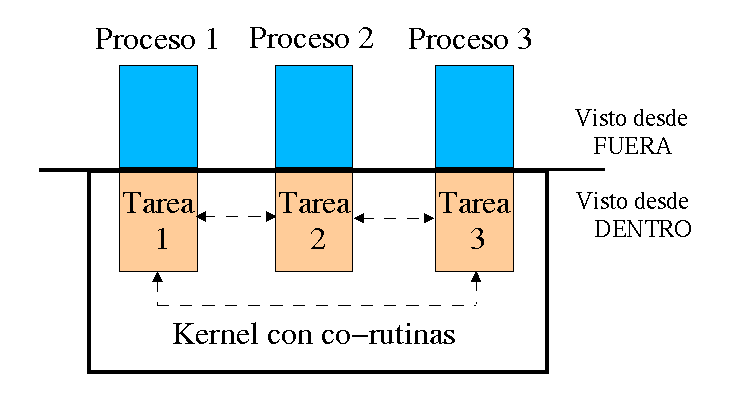
Figura 1 – Los procesos desde una vista interna y externa
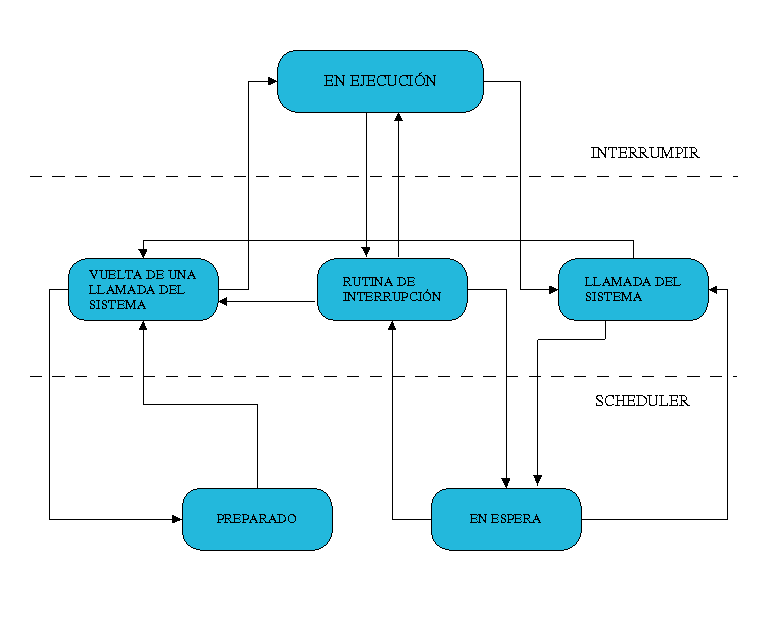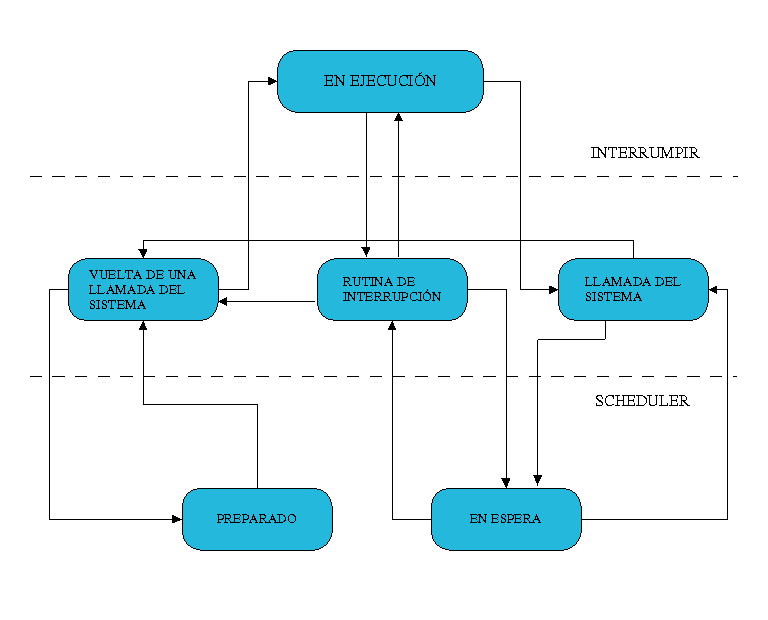
Cuando se ha iniciado un proceso, este puede adquirir distintos estados:
- Ejecución (Running)La tarea está activa y en ejecución. Este proceso solo puede ser interrumpido por una interrupción o una llamada del sistema.
- Rutina interrumpida (Interrupt Routine)Está rutina se activa con una interrupción del sistema (hardware), como puede ser un pulsación del teclado o una llamada del reloj.
- Llamada del Sistema (System Call)Las llamadas del sistema se activan debido a una interrupción producida por el software. Pueden suspender una tarea para llevar acabo un evento.
- En espera (Waiting)El proceso está en espera de un evento externo.
- Vuelta de la llamada del sistema (Return from system call)Este estado se adopta automáticamente después de una llamada del sistema y algunas interrupciones.
- Preparado (Ready)El proceso está en espera de ser atendido por el procesador, que está ocupado con otro proceso en ese momento.
Estos estados no pueden ser adquiridos sin orden alguno o porque sí, sino que llevan un ciclo el cual debe ser respetado. Además, como veremos en el siguiente apartado, si observamos la Figura 3 podremos observar que estos procesos no son “islas” independientes unas de otras, sino que hay una relación familiar entre ellos.
En muchos sistemas operativos actuales se hace la distinción entre procesos y threads. Un thread es una especie de rama o camino en la ejecución de un programa que puede ser procesado en paralelo con otros threads.
Linux no hace esa distinción. En el kernel, únicamente existe el concepto de un proceso, el cual puede compartir recursos con otros procesos. Por eso, una tarea es una generalización del concepto de un thread.
2.2 PRINCIPALES ESTRUCTURAS DE DATOS
2.2.1 La estructura Tarea
En un sistema multitarea es muy importante como una tarea está definida. Es, probablemente, una de los conceptos más importantes en un sistema operativo de este tipo. De hecho los algoritmos usados en Linux para su manejo constituyen la mayor parte del código del kernel.
La descripción de las características de un proceso, vienen dadas por la estructura task_struct. Una de las variables usadas es la llamada state, que es la encargada de almacenar el estado actual de la tarea (los valores que puede tomar esta variable los podemos ver en la Figura 2). Otras variables son counter, que es la variable usada por el Programador (scheduler) para seleccionar el siguiente proceso, o signal que contiene un máscara de un bit (bit mask) para las señales recibidas por el proceso.
Todos los procesos creados son introducidos en una lista doblemente enlazada gracias a los dos punteros siguientes (el comienzo y final de esta lista están almacenados en la variable global init_task):
struct task_struct *next_task;
struct task_struct *previous_task;
En un sistema Unix, los procesos no existen independientemente unos de otros, sino que cada proceso está relacionado con los demás, siguiendo una jerarquía familiar según que proceso lo haya creado, y que al igual que los anteriores están representados por:
struct task_struct p_opptr; /* Padre original */
struct task_struct p_pptr; /* Padre */
struct task_struct p_cptr; /* Hijo más joven */
STRUCT TASK_STRUCT P_YSPTR; /* YOUNGER SIBLING */
struct task_struct p_osptr; /* OLDER SIBLING */
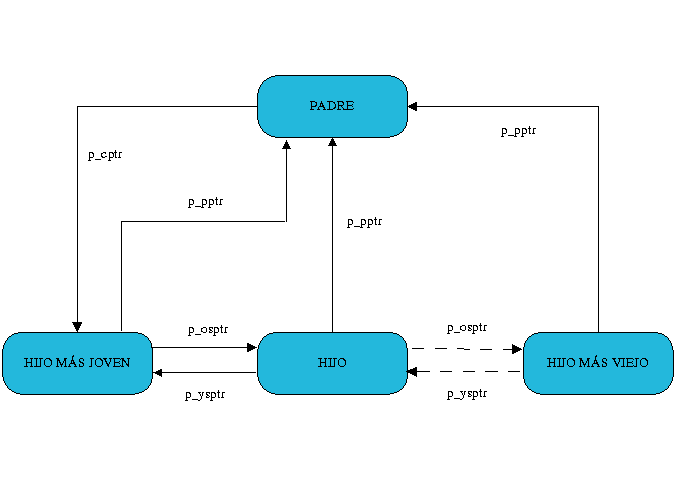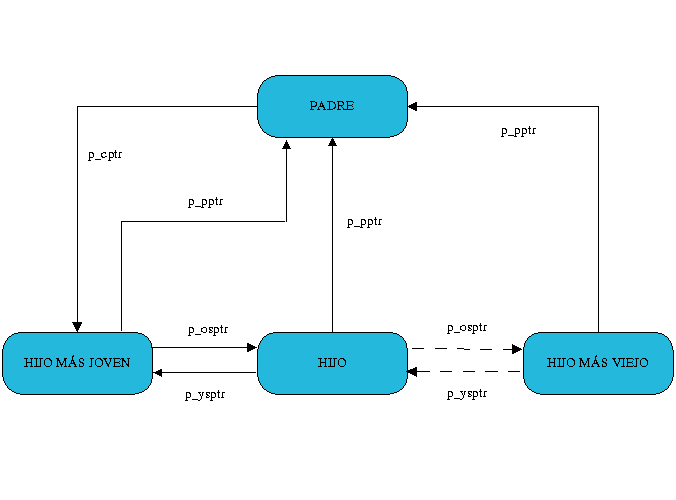
Figura 3 – Relaciones entre procesos
Otras características de esta estructura son, por ejemplo, que cada proceso posee su propia subestructura para el almacenamiento de datos, o que cada proceso posee un numero identificativo pid, a partir del cual se nos facilitará el manejo de dicha tarea.
2.2.2 La tabla de procesos
Cada proceso en ejecución que haya en el ordenador, ocupa una entrada en la tabla de proceso, la cual está restringida aen tamaño a NR_TASKS.
En Linux, la tarea 0 (task[0]) es INIT_TASK, por lo que será la primera tarea cargada por el kernel. Esto es así por que ella será la encargada de lanzar el resto de tareas, como los demonios cargados en el inicio (p.ej. lpd) o el controlador del ratón (gpm).
2.2.3 Ficheros e inodes
En los sistemas UNIX se ha hecho tradicionalmente una distinción entre la estructura de archivos y la de inodes. La estructura inode describe un archivo, aunque esto puede ser visto de diferentes formas: por ejemplo, la estructura de datos en el kernel y la del disco duro describen archivos, y, a pesar de ser distintas, se denominan inodes.
Los inodes contienen información del archivo como propietario, derechos, etc. Cada fichero usado en el sistema se apareja con una única entrada de inode en el kernel, la cual describe diferentes atributos y propiedades del archivo al que corresponde.
2.3 PRINCIPALES MECANISMOS DEL KERNEL
2.3.1 Señales
Desde los primeros sistemas UNIX, esta característica ha sido un de las que más ventajas le han aportado: el uso de señales. Éstas son usadas por el kernel para informar a los procesos sobre ciertos eventos, lo que permite abortarlos o cambiarlos de un estado a otro.
Todas estas señales son enviadas con la función send_sig(), la cual admite el paso de tres parámetros, siendo éstos: el numero de la señal, una descripción del proceso que va a recibir la señal (o mejor dicho, un puntero a la entrada del proceso en cuestión en la tabla de procesos), y opcionalmente la prioridad del proceso que envía la señal. Este último argumento puede tener dos valores: desde el kernel, el cual puede enviar señales a cualquier proceso, o desde un proceso, para lo que es necesario que éste último tenga derechos de superusuario, o bien que tener el mismo UID y GID que el proceso al que se le envía la señal.
2.3.2 Tuberías
Las tuberías o pipes (… | …) son unos enlaces que se pueden realizar con cualquier shell, que unen las entradas de algunos programas con las salidas de los otros. Gracias a esto es posible usar gran parte de los comandos de Linux como filtros y, así, construir comandos más potentes a partir de comandos sencillos. Estas pipes, son consideradas como el método clásico de comunicación entre procesos.
Otra variante de las tuberías son los FIFOs (First In, First Out), que se diferencian de las anteriores en que los FIFOs no son objetos temporales, sino que ellos pueden ser establecidos en un sistema de ficheros.
2.3.3 Interrupciones
Las interrupciones son usadas para permitir al hardware comunicarse con el sistema operativo. En Linux hay dos tipos de interrupciones: rápidas y lentas. Se podría decir que son tres tipos, considerando el tercero como las llamadas del sistema, también desencadenadas por interrupciones.
- Interrupciones lentas: Son las más usuales. Se caracterizan porque se puede llevar a cabo otras interrupciones mientras éstas son tratadas. Después de que una interrupción lenta haya sido procesada, otras tareas adicionales, de carácter periódico, son llevadas a cabo por el sistema (como por ejemplo el scheduler). Un ejemplo típico de interrupción lenta es la interrupción del reloj.
- Interrupciones rápidas: Éstas se usan para tareas más cortas y menos complejas que las comentadas en el apartado anterior. Mientras este tipo de interrupciones son llevadas a cabo, el resto de interrupciones son bloqueadas, a menos que la propia rutina en ejecución las active. Un ejemplo de este tipo de rutinas es la interrupción de teclado.
En ambos tipos de interrupciones el proceso que se lleva a cabo es muy similar: primero todos los registros son salvados con SAVE_ALL y la interrupción envía una confirmación al controlador de interrupciones con ACK. En caso de un sistema con múltiples procesadores, se ejecuta una llamada a la rutina del kernel ENTER_KERNEL para sincronizar el acceso al kernel de los procesadores. Una vez se ha completado la interrupción, se ejecuta la rutina RESTOREMOST que devuelve los registros guardados previamente a sus valores iniciales, llamando después a_iret para continuar con el proceso interrumpido.
2.3.4 Iniciando el sistema
LILO es el encargado de encontrar el kernel de Linux y lo carga a la memoria, iniciándolo en el punto start:, que es donde se encuentra el código en ensamblador encargado de inicializar el hardware esencial. Una vez esto se ha llevado a cabo, el proceso se cambia a Modo Protegido. La instrucción en ensamblador
jmp 0x1000, KERNEL_CS
inicia un salto a la dirección de comienzo del código de 32 bit para el kernel del sistema operativo actual y continua desde startup_32:. En este punto se inician más secciones del hardware (en particular el MMU, el co-procesador y la tabla de descripciones de interrupciones) y el entorno requerido para la ejecución de funciones en C. Una vez esto se ha llevado a cabo, la primera función en C, start_kernel(), es llamada, la cual salvará todos los datos que el código ensamblador ha encontrado sobre el hardware hasta este punto. Entonces se inicializan todas las áreas del kernel.
asmlinkage void start_kernel(void)
{
memory_start = paging_init(memory_start,memory_end);
trap_init();
init_IRQ();
sched_init();
time_init();
parse_options(command_line);
init_modules();
memory_start = console_init(memory_start,memory_end);
memory_start = pci_init(memory_start,memory_end);
memory_start = kmalloc_init(memory_start,memory_end);
sti();
memory_start = inode_nit(memory_start,memory_end);
memory_start = file_table_init(memory_start,memory_end);
memory_start = name_cache_init(memory_start,memory_end);
mem_init(memory_start,memory_end);
buffer_init();
ipc_init();
...
El proceso actualmente en curso es el proceso 0, el cual ejecuta la función init(), que será la encargada de llevar a cabo el resto de la inicialización, cargando los demonios bdflush y kswap. Entonces se hace una llamada a setup, que será la encargada de montar el sistema de archivos root.
2.3.5 Interrupción del Reloj
Todos los sistemas operativos necesitan una forma de medir el tiempo y de mantener una hora en el sistema. El sistema de medida se implementa normalmente haciendo interrupciones en intervalos ya predefinidos. Bajo Linux, el tiempo se mide en ticks desde que el sistema es arrancado. Un tick representa 10 milisegundos, así que la interrupción del reloj se efectúa 100 veces por segundo.
El tiempo se almacena en la variable
unsigned long volatile jiffies;
la cual deberá ser modificado únicamente por esta interrupción. Sin embargo, este método provee solo de un base interna de tiempo.
La interrupción del reloj es llamada relativamente a menudo y, por eso, es un tanto dependiente del tiempo.
La rutina de interrupción en la versión 2.0, simplemente actualiza la variable jiffies y marca como activa una parte de la interrupción del reloj, la cual es llamada por el sistema más adelante, y se desarrolla el resto del trabajo. Como pueden ocurrir varias interrupciones de reloj antes de activar el resto de rutinas, la interrupción del reloj también puede incrementar las variables
unsigned long lost_ticks;
unsigned long lost_ticks_system;
para que así estas puedan ser evaluadas al final de la rutina.
lost_ticks cuenta las interrupciones de reloj producidas desde la ultima activación; lost_ticks_system cuenta, en cambio el numero de interrupciones transcurridas mientras el proceso de interrupción estaba en Modo de Sistema.
A mi parecer opino que un comentario más extenso de este apartado se sale excesivamente del ideal de este apartado, que no es más que una leve introducción al funcionamiento de los algoritmos y procesos más importantes usados en el kernel. Si alguien quiere más información sobre éste, o algunos de los apartados incluidos en el punto 3.3,le aconsejo que consulte el libro [BBD+97], capítulo 3, el único inconveniente es para aquellos que no se desenvuelvan bien con el inglés, aunque si alguien está interesado es un muy buen libro para conocer el funcionamiento del kernel con mayor precisión.
2.4 EL SISTEMA DE ARCHIVOS DE LINUX
Actualmente es normal encontrar un PC con su disco duro con distintas particiones, cada una de ellas con un sistema de ficheros distinta. Esta variedad es debida a que prácticamente cada sistema operativo tiene su propio sistema de ficheros, alegando que éste es más rápido y seguro que el resto.
Puede que una de las razones por las que Linux ha tenido tanta popularidad, sea por la cantidad de sistemas de ficheros distintos que soporta (FAT16 y FAT32 de Windows, NTFS de WinNT, HPFS de OS/2, ISO 9660 y Joliet, que son los estándares más comunes en CD, etc.). El soporte de esta gran cantidad de sistema de ficheros es debido a la interfaz unificada que usa el kernel llamada Virtual File System Switch (VFS) o más sencillamente Virtual File System. Este sistema virtual de ficheros es el encargado de cada proceso pueda manejar información desde los distintos ficheros sin necesidad de saber donde se encuentran, o de saber si pertenecen a un tipo de sistema de ficheros u otro.
Toda la información obtenida en este apartado ha sido obtenida a partir del libro [BBD+97] y de la página web [Rusling98], los cuales recomiendo para todo aquel que esté interesado en profundizar en este tema. Como nota comentar que, como ya hemos dicho antes, [BBD+97] está en inglés, y la web [Rusling98] aunque el original está en inglés, se puede encontrar una traducción al castellano, aunque en estas fechas (Mayo 2000) se encuentra en fase de desarrollo, por lo que hay secciones traducidas parcialmente, así como también otras no traducidas.
2.4.1 Conocimientos básicos
La CPU no es el único elemento “inteligente” que existe en la computadora. Cada elemento hardware que la compone lleva incluido su propio controlador (por ejemplo el ratón y el teclado son controlados por el chip SuperIO, el disco IDE por el controlador IDE o el SCSI por la controladora SCSI). Esto implica que el acceso a cada uno de estos dispositivos se realizará de forma distinta, por lo que cada utilidad debería incluir unos controladores. En vez de eso, los controladores se incluyen en el kernel como unas librerías conocidas como device drivers (controlador de dispositivo), de tal forma que se puede acceder a todos los dispositivos así configurados, sin necesidad de conocer cómo funciona el dispositivo a bajo nivel. De esta forma se consigue una abstracción en lo que se refiere al acceso a dispositivos.
En Linux, como en Unix, a los distintos sistemas de ficheros que el sistema puede usar no se accede por identificadores de dispositivo (como un número o nombre de unidad) pero, en cambio se combinan en una estructura jerárquica de árbol que representa el sistema de ficheros como una entidad única y sencilla. Linux añade cada sistema de ficheros nuevo en este árbol de sistemas de ficheros cuando se monta. Todos los sistemas de ficheros, de cualquier tipo, se montan sobre un directorio y los ficheros del sistema de ficheros son el contenido de ese directorio. Este directorio se conoce como directorio de montaje o punto de montaje. Cuando el sistema de ficheros se desmonta, los ficheros propios del directorio de montaje son visibles de nuevo.
Además, gracias a esta forma de trabajo, no es necesario implementar el código necesario para acceder a los distintos dispositivos, sino que cada proceso se comunica con los dispositivos que necesite a través del acceso que le es proporcionado a través del VFS, como se puede observar en la figura siguiente.
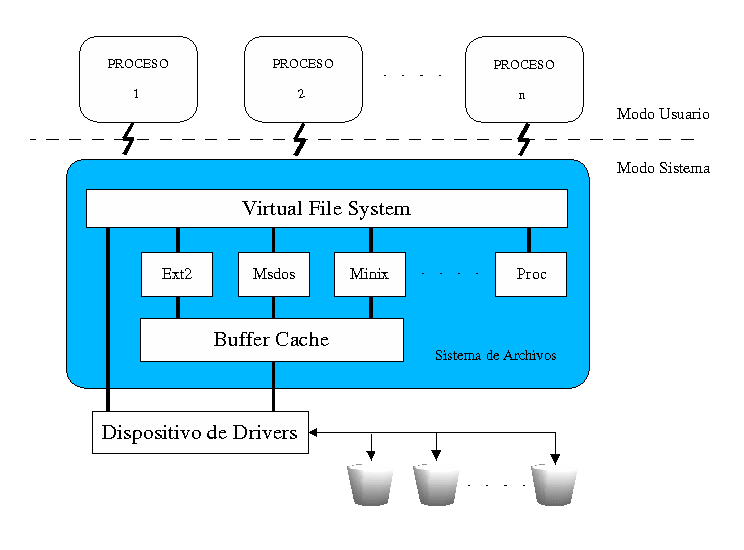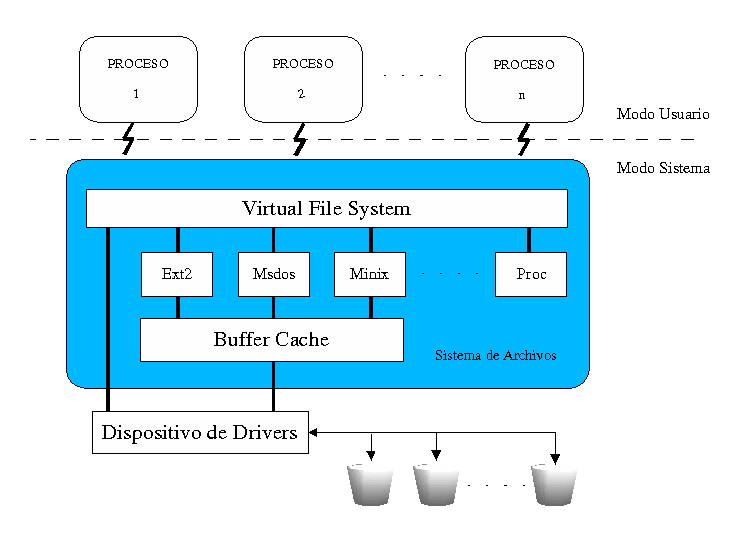
El primer sistema de ficheros diseñado específicamente para Linux, el sistema de Ficheros Extendido, o EXT, fue introducido en Abril de 1992 y solventó muchos problemas pero era aún falto de rapidez. Así, en 1993, el Segundo sistema de Ficheros Extendido, o EXT2, fue añadido al kernel como sistema principal de ficheros.
En ese momento un importante desarrollo tuvo lugar en Linux. El sistema de ficheros real se separó del sistema operativo y servicios del sistema a favor de un interfaz conocido como el Sistema de Ficheros Virtual, o VFS. VFS permite a Linux soportar muchos, incluso muy diferentes, sistemas de ficheros, cada uno presentando un interfaz software común a través del VFS. Todos los detalles del sistema de ficheros de Linux son traducidos mediante software de forma que todo el sistema de ficheros parece idéntico al resto del kernel de Linux y a los programas que se ejecutan en el sistema. La capa del sistema de Ficheros Virtual de Linux permite al usuario montar de forma transparente diferentes sistemas de ficheros al mismo tiempo.
El sistema de Ficheros Virtual está implementado de forma que el acceso a los ficheros es tan rápido y eficiente como sea posible. También debe asegurar que los ficheros y los datos que contiene son correctos. Estos dos requisitos pueden ser incompatibles entre si. El VFS de Linux mantiene una antememoria con información de cada sistema de ficheros montado y en uso. Se debe tener mucho cuidado al actualizar correctamente el sistema de ficheros ya que los datos contenidos en las antememorias se modifican cuando se crean, escriben y borran ficheros y directorios. Si se pudieran ver las estructuras de datos del sistema de ficheros dentro del kernel en ejecución, se podría ver los bloques de datos que se leen y escriben por el sistema de ficheros. Las estructuras de datos, que describen los ficheros y directorios que son accedidos serian creadas y destruidas y todo el tiempo los controladores de los dispositivo estarían trabajando, buscando y guardando datos. La antememoria o caché más importantes es la llamada Buffer Cache, que está integrada entre cada sistema de ficheros y su dispositivo de bloque. Tal y como se accede a los bloques se ponen en el Buffer Cache y se almacenan en varias colas dependiendo de sus estados. El Buffer Cache no sólo mantiene buffers de datos, también ayuda a administrar el interfaz asíncrono con los controladores de dispositivos de bloque.
2.4.2 El Virtual File System
Como en el sistema de ficheros EXT2, cada fichero, directorio y demás se representan en el VFS por un y sólo un inodo VFS. La información en cada inodo VFS se construye a partir de información del sistema de ficheros por las rutinas específicas del sistema de ficheros. Los inodos VFS existen sólo en la memoria del núcleo y se mantienen en el caché de inodos VFS tanto tiempo como sean útiles para el sistema. Entre otra información, los inodos VFS contienen los siguientes campos:
- device: Este es el identificador de dispositivo del dispositivo que contiene el fichero o lo que este inodo VFS represente,
- inode number: Este es el número del inodo y es único en este sistema de ficheros. La combinación de device y inode number es única dentro del Sistema de Ficheros Virtual,
- mode: Como en EXT2 este campo describe qué representa este inodo VFS y los permisos de acceso (r-lectura, w-escritura, x-ejecución para propietario, grupo y otros usuarios),
- user ids: Los identificadores de propietario,
- times: Los tiempos de creación, modificación y escritura,
- block size: El tamaño de bloque en bytes para este fichero, por ejemplo 1024 bytes,
- inode operations: Un puntero a un bloque de direcciones de rutina. Estas rutinas son específicas del sistema de ficheros y realizan operaciones para este inodo, por ejemplo, truncar el fichero que representa este inodo.
- count: El número de componentes del sistema que están usando actualmente este inodo VFS. Un contador de cero indica que el inodo está libre para ser descartado o rehusado,
- lock: Este campo se usa para bloquear el inodo VFS, por ejemplo, cuando se lee del sistema de ficheros,
- dirty: Indica si se ha escrito en este inodo, si es así, el sistema de ficheros necesitará modificarlo,
- file system specific information.
2.4.3 El sistema de ficheros Ext2
El Segundo sistema de ficheros Extendido de Linux ha sido el que mayor éxito ha cosechado, siendo básico en cualquier distribución de este S.O. Su construcción se basa en que los datos son guardados en bloques, los cuales son, en principio, del mismo tamaño, aunque pueden variar de un sistema a otro (ya que esta elección del tamaño se hace al crear el sistema con mke2fs). Cuando se almacena un fichero, se hace de tal forma que ocupe un número entero de bloques, quedando gran parte de la capacidad del último bloque usado bastante desperdiciada, a no ser que el fichero de datos ocupe exactamente un numero de bloques. No todos los bloques del sistema de ficheros contienen datos, algunos deben usarse para mantener la información que describe la estructura del sistema de ficheros. EXT2 define la topología del sistema de ficheros describiendo cada fichero del sistema con una estructura de datos inodo. Un inodo describe que bloques ocupan los datos de un fichero y también los permisos de acceso del fichero, las horas de modificación del fichero y el tipo del fichero. Cada fichero en el sistema de ficheros EXT2 se describe por un único inodo y cada inodo tiene un único número que lo identifica. Los inodos del sistema de ficheros se almacenan juntos en tablas de inodos. Los directorios EXT2 son simplemente ficheros especiales (ellos mismos descritos por inodos) que contienen punteros a los inodos de sus entradas de directorio.
El sistema de ficheros EXT2 divide las particiones lógicas que ocupa en Grupos de Bloque (Block Groups). Cada grupo duplica información crítica para la integridad del sistema de ficheros ya sea valiéndose de ficheros y directorios como de bloques de información y datos. Esta duplicación es necesaria por si ocurriera un desastre y el sistema de ficheros necesitara recuperarse.
En el sistema de ficheros EXT2, el inodo es el bloque de construcción básico; cada fichero y directorio del sistema de ficheros es descrito por un y sólo un inodo. Los inodos EXT2 para cada Grupo de Bloque se almacenan juntos en la tabla de inodos con un mapa de bits que permite al sistema seguir la pista de inodos reservados y libres. Un inodo EXT2, entre otra información, contiene los siguientes campos:
- mode: Esto mantiene dos partes de información; qué inodo describe y los permisos que tienen los usuarios. Para EXT2, un inodo puede describir un ficheros, directorio, enlace simbólico, dispositivo de bloque, dispositivo de carácter o FIFO.
- owner Information: Los identificadores de usuario y grupo de los dueños de este fichero o directorio. Esto permite al sistema de ficheros aplicar correctamente el tipo de acceso,
- size: El tamaño en del fichero en bytes,
- timestamps: La hora en la que el inodo fue creado y la última hora en que se modificó,
- datablocks: Punteros a los bloques que contienen los datos que este inodo describe. Los doce primeros son punteros a los bloques físicos que contienen los datos descritos por este inodo y los tres últimos punteros contienen más y más niveles de indirección. Por ejemplo, el puntero de doble indirección apunta a un bloque de punteros que apuntan a bloques de punteros que apuntan a bloques de datos. Esto significa que ficheros menores o iguales a doce bloques de datos en longitud son más fácilmente accedidos que ficheros más grandes.
Los inodos EXT2 pueden describir ficheros de dispositivo especiales. No son ficheros reales pero permiten que los programas puedan usarlos para acceder a los dispositivos. Todos los ficheros de dispositivo de /dev están ahí para permitir a los programas acceder a los dispositivos de Linux. Por ejemplo el programa mount toma como argumento el fichero de dispositivo que el usuario desee montar.
El Superbloque contiene una descripción del tamaño y forma base del sistema de ficheros. La información contenida permite al administrador del sistema de ficheros usar y mantener el sistema de ficheros. Normalmente sólo se lee el Superbloque del Grupo de Bloque 0 cuando se monta el sistema de ficheros pero cada Grupo de Bloque contiene una copia duplicada en caso de que se corrompa sistema de ficheros. Entre otra información contiene:
- Magic Number: Esto permite al software de montaje comprobar que es realmente el Superbloque para un sistema de ficheros EXT2. Para la versión actual de EXT2 éste es 0xEF53.
- Revision Level: Los niveles de revisión mayor y menor permiten al código de montaje determinar si este sistema de ficheros soporta o no características que sólo son disponibles para revisiones particulares del sistema de ficheros. También hay campos de compatibilidad que ayudan al código de montaje determinar que nuevas características se pueden usar con seguridad en ese sistema de ficheros,
- Mount Count and Maximum Mount Count: Juntos permiten al sistema determinar si el sistema de ficheros fue comprobado correctamente. El contador de montaje se incrementa cada vez que se monta el sistema de ficheros y cuando es igual al contador máximo de montaje muestra el mensaje de aviso «maximal mount count reached, running e2fsck is recommended»,
- Block Group Number: El número del Grupo de Bloque que tiene la copia de este Superbloque,
- Block Size: El tamaño de bloque para este sistema de ficheros en bytes, por ejemplo 1024 bytes,
- Blocks per Group: El número de bloques en un grupo. Como el tamaño de bloque éste se fija cuando se crea el sistema de ficheros,
- Free Blocks: EL número de bloques libres en el sistema de ficheros,
- Free Inodes: El número de Inodos libres en el sistema de ficheros,
- First Inode: Este es el número de inodo del primer inodo en el sistema de ficheros. El primer inodo en un sistema de ficheros EXT2 raíz seria la entrada directorio para el directorio ‘/’.
2.4.4 Sistema de Ficheros Proc
El sistema de ficheros /proc muestra realmente la potencia del Sistema Virtual de Ficheros. Este sistema no existe en realidad. Éste como el resto de sistemas de ficheros, se registra en el VFS. Sin embargo, cuando el VFS hace llamadas al /proc, éste crea los ficheros que le son pedidos con información sobre el kernel. Por ejemplo la llamada al fichero /proc/devices genera a partir de las estructuras del kernel, un archivo describiendo sus dispositivos.
El sistema de ficheros /proc representa una ventana hacia el interior del kernel.
3 La Shell
3.1 ¿Qué es la shell?
Hablando de forma genérica, la shell es cualquier interfaz del sistema UNIX, que coge de la entrada estándar las instrucciones introducidas por el usuario, las traduce a instrucciones que el sistema operativo es capaz de interpretar, y devuelve generalmente por la salida estándar, los resultados de las instrucciones que el sistema ha ejecutado.
El trabajo básico de la shell es traducir las instrucciones que se introducen en la linea de comandos en instrucciones que el sistema operativo sea capaz de entender. Depende de cómo se realice esta tarea y de las características que éste ofrezca al usuario para realizar una tarea, una shell será más potente que otra si el usuario es capaz de introducir la misma tarea de una forma más rápida que en otra.
3.2 Historia de las Shells de UNIX
La independencia de la shell respecto al sistema operativo, ha permitido desde los primeros pasos de UNIX, la creación de múltiples de shells, aunque solo algunas han conseguido un uso “popular”.
La primera shell más importante fue la Bourne shell, nombre que adquirió de su creador Steven Bourne. Ésta fue incluida en la primera versión popular de UNIX, la Versión 7, sobre el año 1987. El nombre que recibe la Bourne en el sistema operativo es sh. A pesar de los cambios que UNIX pueda haber sufrido, la shell Bourne sigue siendo una de las más populares, dependiendo hoy en día de ella gran cantidad de utilidades.
La primera gran alternativa a esta shell fue la C shell, o también csh. Su creador, Bill Joy en la Universidad de California en Berkeley, la escribió como una parte del Berkeley System Distribution (BSD), versión de UNIX que salió un par de años después de la versión 7. Esta shell está incluida en todas las versiones de UNIX más recientes.
La C shell recibe su nombre debido a la semejanza de sus comandos a las instrucciones del lenguaje C, lo cual hace a la shell más fácil de aprender para los programadores.
En los últimos años han continuado surgiendo diversas shell, cuya popularidad ha ido en aumento. La más notable es la Korn shell, la cual incorpora las mejores cualidades de la shell Bourne y de la C. El único inconveniente de esta shell es que se distribuye de forma comercial. Debido a esta característica otra shell ha tenido un mayor auge, la bash shell, de características semejantes a la korn, pero de distribución gratuita.
3.3 The Bourne Again Shell
La Bourne Again Shell, o también bash, fue creada para uso del proyecto GNU. La intención era que bash fuera la shell estándar de sistema GNU. Su “nacimiento” fue el Domingo 10 de Enero de 1988, y su creador fue Brian Fox, el cual continuó con el desarrollo de esta shell hasta 1993. En 1989 Chet Ramey fue el encargado de numerosas correcciones en la shell, e incluyó muchas nuevas características a ésta, convirtiéndose en el desarrollador oficial a partir de 1993
La principal característica de esta shell, y seguramente, la que le ha dado un mayor auge, al menos en un primer golpe, es el modo de edición en linea de comandos. Con este modo es mucho más fácil volver atrás y corregir errores de escritura en los comandos en vez que tenerlos que volver a introducir completamente. La otra gran ventaja de esta shell frente a las otras es el control del trabajo, con lo que el usuario es capaz de parar, comenzar y pausar cualquier numero de comandos a la vez.
El resto de características de esta shell, son, en su mayoría, para programadores, como por ejemplo la inclusión de nuevas variables para la personalización del entorno, instrucciones avanzadas de I/O o mayor cantidad de estructuras de control, entre otras muchas. Todas estas cualidades sobre la shell Bash, pueden encontrarse en el libro [NR95], que trata todos estos aspectos y muchos más, incluyendo programación en Shell Script, o uso de características avanzadas de esta potente shell.
4 LINUX EN RED
4.1 ¿QUÉ ES UNA RED DE COMPUTADORAS?
La idea de red es probablemente tan vieja como la de las telecomunicaciones. Consideremos a la gente que vivía en la edad de piedra, donde los tambores se habrían utilizado para transmitir mensajes entre individuos. Supongamos que el cavernícola A quiere invitar al cavernícola B a un partido de lanzamiento de rocas contra el otro, pero viven demasiado lejos como para que B oiga a A golpear su tambor. ¿Cuáles son las opciones de A? Podría…
-
Ir a la choza de B.
-
Hacerse con un tambor más grande.
-
Pedirle a C, que vive a mitad camino entre los dos, que retransmita el mensaje.
La última opción es lo que se llama una red.
Así pues, definimos una red como un conjunto de nodos que son capaces de comunicarse entre si, a menudo contando con los servicios de varios nodos especializados que conmutan datos entre participantes. Los nodos suelen ser ordenadores, aunque no es necesario; podemos considerar también terminales X o impresoras inteligentes como nodos. Pequeñas aglomeraciones de nodos también llamadas instalaciones (del inglés site).
La comunicación sería imposible sin algún tipo de lenguaje o código. En las redes de ordenadores, estos lenguajes son los llamados colectivamente protocolos. Sin embargo, no se debe pensar en protocolos escritos, sino más bien en el código de comportamiento altamente formalizado que se observa cuando se encuentran los jefes de estado. De un modo muy similar, los protocolos usados por las redes de ordenadores son normas muy estrictas para el intercambio de mensajes entre dos o más nodos.
Por otra parte, cuando hablamos de redes de ordenadores, a menudo significa hablar de Linux. Linux es un sistema operativo bajo el cual, la tecnología de internet nació.La capacidad de Linux es la misma que pueda tener cualquier sistema de UNIX. Debido a que la tecnología de internet nació en UNIX, otros sistemas operativos están a años luz de lo que UNIX puede ofrecer. Este sistema operativo no es el único con capacidad de red, pero si está considerado como uno de los mejores. Ha habido sistemas operativos tipo UNIX gratuitos para PC, como 386BSD, FreeBSD y Linux. Linux es un sistema operativo que lucha por ofrecer toda la funcionalidad que requieren los estándares POSIX, para sistemas operativos tipo UNIX, aunque es una reimplementación completa, desde cero.
Linux está cubierto por la Licencia Pública General (GPL) GNU, que permite la libre distribución del código. Superando sus males de joven, y atraído por una siempre creciente base de programas de aplicación gratuitos, se está convirtiendo rápidamente en el sistema operativo de elección de muchos usuarios de PC, favorecido en gran parte por una fuerte circulación de dicho código libre a través de Internet.
4.2 REDES UUCP
UUCP es una abreviatura de Unix-to-Unix Copy. Comenzó siendo un paquete de programas para transferir ficheros sobre líneas serie, programar esas transferencias, e iniciar la ejecución de programas en el lugar remoto. Ha experimentado grandes cambios desde su primera implementación a finales de los 70, pero aún es bastante espartano en los servicios que ofrece. Su principal aplicación es todavía en redes de área metropolitanas (WAN) basadas en los enlaces telefónicos.
UUCP comenzó a desarrollarse por los Laboratorios Bell en 1977 para la comunicación entre sus laboratorios de desarrollo de Unix. A mediados de 1978, esta red ya conectaba a más de 80 centros. Se ejecutaban aplicaciones de correo electrónico, así como de impresión remota; sin embargo, el uso principal del sistema era distribuir software nuevo y mejoras. Hoy día UUCP ya no está destinado exclusivamente para el entorno UNIX. Hay versiones disponibles para diversas plataformas.
Una de las principales desventajas de las redes UUCP es su bajo ancho de banda. Por un lado, el equipo telefónico establece un límite rígido en la tasa máxima de transferencia. Por otro lado los enlaces UUCP raramente son conexiones permanentes; en su lugar, los nodos se llaman entre si a intervalos regulares. Es por ello, que la mayoría del tiempo que le lleva a un mensaje viajar por una red UUCP permanece atrapado en el disco de algún nodo, esperando al establecimiento de la próxima conexión.
4.2.1 Funcionamineto de una red UUCP
La idea que hay detrás de UUCP es bastante simple: como su nombre indica, basicamente copia ficheros de un nodo a otro, pero también permite realizar ciertas acciones en el nodo remoto.
Supongamos que nos está permitido que nuestra máquina acceda a un nodo hipotético llamado swim, y le vamos a hacer ejecutar el comando de impresión lpr para nosotros. Entonces, podríamos escribir lo siguiente en nuestra línea de comandos para que nos imprima este documento en swim:
$uux -r swim!lpr !RedesLinux.txt
Esto hace que uux, un comando del repertorio UUCP, planifique un trabajo para swim. Este trabajo consta del fichero de entrada, RedesLinux.txt, y la petición de enviar este fichero a lpr. La opción -r indica a uux que no llame al sistema remoto inmediatamente, sino que almacene el trabajo hasta que establezca la próxima conexión. A esto se le llama spooling, o almacenamiento en la cola.
Otra propiedad de UUCP es que permite reenviar trabajos y ficheros a través de varios nodos, suponiendo que éstos colaboren. Asumiremos que swim, el nodo del ejemplo anterior, tiene un enlace UUCP con groucho, el cual mantiene un gran número de aplicaciones UNIX. Para transferir el fichero tripware-1.0.tar.gz hasta nuestra máquina deberíamos indicarlo así:
uucp -mr swim!groucho!~/security/tripware-1.0.tar.gz trip.tgz
El trabajo creado pedirá a swim que traiga el fichero desde groucho, y lo envie hasta nuestra máquina, donde UUCP lo almacenará en trip.tgz y nos notificará por correo la llegada del fichero. Esto ocurrirá en tres pasos. Primero, nuestra máquina envía el fichero a swim. La siguiente vez que swim establezca contacto con groucho, se transferirá el fichero de groucho a swim. El último paso es la transferencia del mismo desde swim hasta nuestra máquina.
Actualmente, los servicios más importantes que proporcionan las redes UUCP son el correo electrónico y las noticias, aunque también es el medio elegido por muchos servidores de ficheros que ofrecen servicio público. Generalmente podremos acceder a ellos llamando con UUCP, accediendo como usuario invitado, y transferiéndose los archivos desde un área de ficheros públicamente accesible. Estas cuentas de invitado tienen, a menudo, un nombre de acceso y password.
4.3 REDES TCP/IP
4.3.1 TCP/IP frente a UUCP
Aunque UUCP puede resultar una elección razonable para enlaces de red mediante llamada de bajo coste, hay muchas situaciones en las que su técnica de almacenamiento y reenvío se muestra demasiado inflexible, por ejemplo en Redes de Área Local (LANs). Estas redes están compuestas generalmente por un pequeño número de máquinas localizadas en el mismo edificio, o incluso en la misma planta, que están interconectadas para proporcionar un entorno de trabajo homogéneo. Es típico que se quiera compartir ficheros, nodos, o ejecutar aplicaciones distribuidas en diferentes máquinas.
Estas tareas requieren una aproximación completamente diferente a las redes. En lugar de reenviar ficheros completos con una descripción del trabajo, todos los datos se fragmentan en pequeñas unidades (paquetes), que se envían inmediatamente al nodo destino, donde son reensamblados. Este tipo de redes se llaman redes de intercambio de paquetes. Entre otras cosas, esto permite ejecutar aplicaciones interactivas a través de la red. El coste de esto supone, por supuesto una complejidad adicional al software.
La solución que han adoptado los sistemas UNIX (y muchos no UNIX) es conocida como TCP/IP.
4.3.2 Introducción a las redes TCP/IP
El TCP/IP tiene sus orígenes en un proyecto de investigación fundado en Estados Unidos por DARPA (Defense Advanced Research Projects Agency – Agencia de Proyectos Avanzados de Investigación en Defensa) en 1969. Ésta fue una red experimental, la red ARPANET, que pasó a ser operativa en 1975, después de haber demostrado ser un éxito.
En 1983, fue adoptado como estándar el nuevo conjunto de protocolos TCP/IP, y todos los nodos de la red pasaron a utilizarlo. Cuando ARPANET por fin dio paso a Internet (con la propia ARPANET integrándose en su existencia en 1990), el uso del TCP/IP se había extendido a redes más allá de la propia Internet. Las más destacables son las redes locales UNIX, pero con la llegada de los equipos telefónicos digitales rápidos, como la RDSI, también tiene un futuro prometedor como transporte en redes telefónicas.
Tomaremos como ejemplo una red típica: la de una universidad, concretamente la hipotética Universidad Groucho Marx (GMU). En esta universidad, la mayoría de los departamentos mantienen sus propias redes de área local, mientras que algunos comparten una, y otros poseen varias. Todos ellos están interconectados, y están enganchados a Internet a través de un solo enlace de alta velocidad.
Supongamos una máquina Linux conectada a una LAN de nodos UNIX en el Departamento de Matemáticas, siendo su nombre erdos, que intenta conectar con un nodo del Departamento de Físicas, por ejemplo quark.
En línea de comandos, introduciremos nuestro nombre de acceso y nuestra clave. Entonces dispondremos de una shell de quark, sobre la que podemos escribir como si estuvieramos sentados en la consola del sistema. Tras salir del shell volveremos a tener la línea de comandos de nuestra propia máquina. Acabamos de utilizar una de las aplicaciones de interactividad instantánea que proporciona TCP/IP: el acceso remoto.
Mientras estemos conectados a quark, podríamos también desear ejecutar una aplicación X. Para ello, si ponemos en marcha ahora nuestra aplicación, esta contactará con nuestro servidor X en lugar de quark, y mostrará todas las ventanas en nuestro munitor. Por supuesto, esto requiere que estemos ejecutando X11 en erdos. La clave está en que TCP/IP permite a quark y a erdos enviarse paquetes X11 en ambos sentidos para darnos la impresión de que estamos en un único sistema. La red es casi transparente en este caso.
Otra aplicación muy importante en redes TCP/IP es NFS, abreviatura de Network File System (Sistema de Ficheros de Red). Es otra forma de hacer transparente la red, porque básicamente permite montar jerarquías de directorios de otras máquinas, de modo que aparezcan como sistemas de ficheros locales. Por ejemplo, todos los directorios “home”, o personales, de los usuarios pueden estar en una máquina servidor central, desde la cual montan los directorios el resto de máquinas de la LAN. El efecto de esto es que los usuarios pueden acceder a cualquier máquina, y encontrarse a sí mismos en el mismo directorio. De forma similar, es posible instalar aplicaciones que requieren gran cantidad en disco en una única máquina, y exportar estos directorios a otras máquinas.
Por supuesto, esto son sólo ejemplos de lo que se puede hacer en un entorno de redes TCP/IP: las posibilidades son casi ilimitadas.
4.4 HARDWARE
4.4.1 Ethernets
El tipo de hardware más utilizado en LANs es lo que comunmente conocemos como Ethernet. Consta de un solo cable con los nodos colgando de él a través de conectores, clavijas o transceptores. Las ethernet simples, son baratas de instalar, lo que unido a un flujo de transferencia neto de 10 Megabits por segundo, avala gran parte de su popularidad.
Hay tres tipos de Ethernet, en función de su cable, llamadas gruesas, finas y de par trenzado. Tanto el fino como el grueso utilizan cable coaxial, variando en el grosor y el modo de conectar este cable a los nodos. El Ethernet fino emplea conectores “BCN” con forma de T, que se pinchan en el cable y se enganchan a los conectores de la parte trasera del ordenador. El Ethernet grueso requiere que se realice un pequeño agujero en el cable, y conecte un transceptor utilizando un “nodo vampiro”. Entonces se puede conectar uno o más nodos al transceptor. Los cables Ethernet fino y grueso pueden alcanzar una distancia de 200 y 500 metros, respectivamente, y es por ello que se les llama también 10base-2 y 10base-5. El par trenzado usa un cable hecho de dos hilos de cobre como las que se encuentran en las instalaciones telefónicas ordinarias, pero generalmente necesitan hardware adicional. También se conoce como 10base-T.
A pesar de que añadir un nodo a una Ethernet gruesa es un poco lioso, eso no tirará abajo la red; sin embargo, para añadir un nodo en una instalación de cable fino, se debe interrumpir el servicio de red al menos por unos minutos ya que se debe cortar el cable para insertar el conector. Es por ello que para instalaciones de gran escala es más apropiado el Ethernet grueso.
Uno de los inconvenientes de la tecnología Ethernet es su limitada longitud de cable, que imposibilita cualquier uso fuera de las LANs. Sin embargo, pueden enlazarse varios segmentos de Ethernet entre si utilizando repetidores, puentes o encaminadores (repeaters, bridges y routers, respectivamente). Los repetidores simplemente copian las señales entre dos o más segmentos, de forma que todos los segmentos juntos actúan como si fuese una única Ethernet. Debido a requisitos de tiempos, no puede haber más de cuatro repetidores entre cualquier par de nodos de la red. Los puentes y encaminadores son más sofisticados, analizan los datos de entrada y los reenvían sólo si el nodo no está en la Ethernet local.
Ethernet funciona como un sistema de bus, donde un nodo puede mandar paquetes (o tramas) de hasta 1500 bytes a otro nodo de la misma Ethernet. Cada nodo se direcciona por una dirección de bytes grabada en el firmware de su tarjeta Ethernet. Estas direcciones se especifican generalmente como una secuencia de números hexadecimales de dos dígitos separados por dos puntos, como en aa:bb:cc:dd:ee:ff.
Una trama enviada por una estación la ven todas las estaciones conectadas, pero sólo el nodo destinatario la toma y procesa. Si dos estaciones intentan emitir al mismo tiempo, se produce una colisión, que se resuelve por parte de las dos estaciones abortando el envío, y reintentándolo al cabo de un rato.
4.4.2 Otros tipos de hardware
En instalaciones mayores como la Universidad de Groucho Marx, Ethernet no es el único tipo de red que puede utilizarse. En la UNiversidad de Groucho Marx cada LAN de un departamento está enlazada a la troncal del campus, que es un cable de fibra óptica funcionando en FDDI (Fiber Distributed Data Interface). FDDI emplea un enfoque totalmente diferente para transmitir datos, que básicamente implica el envío de un número de testigos, de modo que una estación sólo pueda enviar una trama si captura un testigo. La principal ventaja de FDDI es una velocidad de hasta 100 Mbps, y una longitud de cable máxima de hasta 200 km.
Para enlaces de red de larga distancia, se utiliza frecuentemente un tipo distinto de equipos, que se basa en el estándar X.25. Muchas de las llamadas Redes Públicas de Datos ofrecen este servicio. X.25 requiere un hardware especial, llamado Ensamblador/Desensamblador de Paquetes o PAD. X.25 define un conjunto de protocolos de red de derecho propio, pero sin embargo se usa frecuentemente para conectar redes bajo TCP/IP y otros protocolos. Ya que los paquetes IP no se pueden convertir de forma simple en X.25 (y viceversa), éstos deben ser encapsulados en paquetes X.25 y enviados a través de la red.
Otras técnicas implican el uso de las lentas pero baratas líneas serie para acceder bajo demanda. Esto requiere aun otros protocolos para la transmisión de paquetes, como SLIP o PPP.
4.5 PROTOCOLOS
4.5.1 El protocolo IP (internet protocol)
En instalaciones grandes como la Universidad Groucho Marx, habrá varias Ethernets separadas, que han de conectarse de alguna manera. En la GMU, el departamento de matemáticas tiene dos Ethernets: una red de máquinas rápidas para profesores y graduados, y otra con máquinas más lentas para estudiantes. Ambas redes están colgadas de la red troncal FDDI del campus.
Esta conexión se gestiona con un nodo dedicado, denominado pasarela, o gateway (Figura 5), que maneja los paquetes entrantes y salientes copiándolos entre las dos Ethernets y el cable de fibra óptica. Por ejemplo, si nos encontramos en el Departamento de Matemáticas, y queremos acceder a quark situada en la LAN del Departamento de Físicas desde nuestra máquina Linux, el software de red no puede mandar paquetes a quark directamente, porque no está en la misma Ethernet. Por tanto, tenemos que confiar en la pasarela para que actúe como retransmisor. La pasarela (llamemosla sophus) reenvía entonces estos paquetes a su pasarela homóloga niels del Departamento de Físicas, usando la troncal, y por fin niels los entrega a la máquina destino.
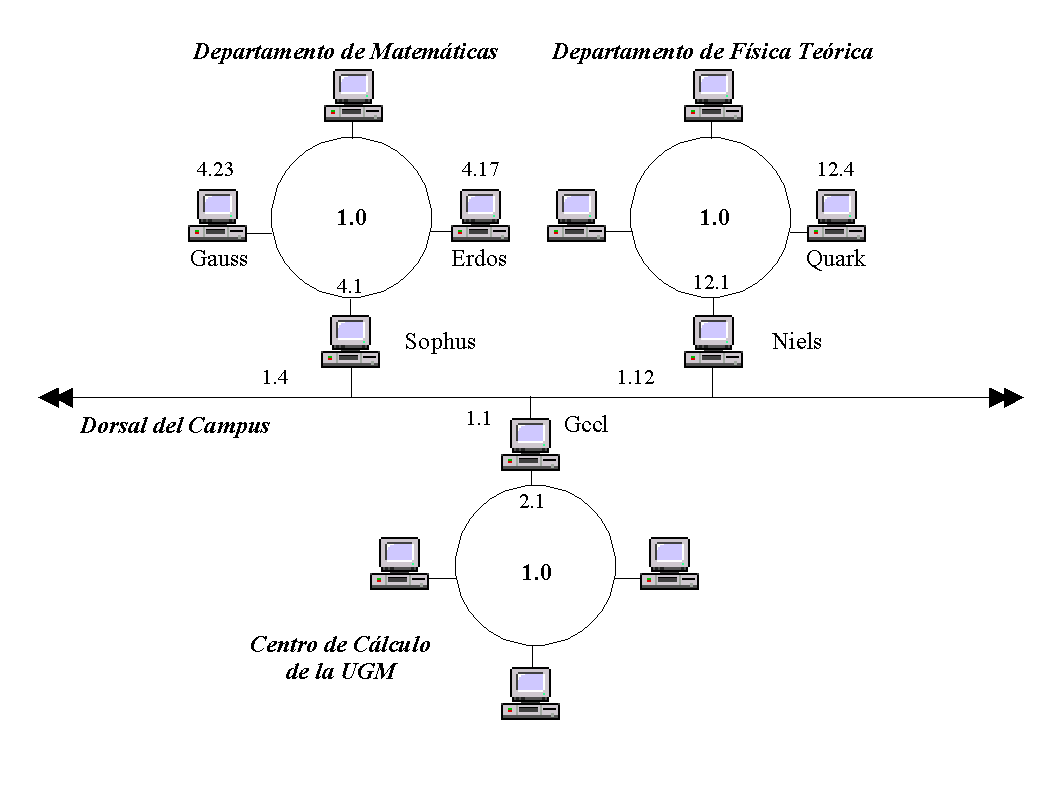
Este esquema de envío de datos al nodo remoto se llama encaminamiento, y en este contexto a los paquetes se les denomina a menudo datagramas. Para facilitar las cosas, el intercambio de datagramas está gobernado por un único protocolo que es independiente del hardware utilizado: IP.
El principal beneficio del IP es que conviene a redes físicamente distintas en una red aparentemente homogénea. A esto se le llama internetworking (interconexión de redes), y a la resultante “meta-red” se la denomina internet. Observese aqui la sutil diferencia entre una internet y _La_Internet. El último es el nombre oficial de una internet global particular.
Claro que el IP también necesita un esquema de direccionamiento independiente del hardware. Esto se consigue asignando a cada nodo un número único de 32 bits, que define su dirección IP. Una dirección IP se escribe normalmente como 4 números en decimal, uno por cada división de 8 bits, y separados por puntos. Por ejemplo, quark podría tener una dirección IP 0x954C0C04, que se escribiría como 145.76.12.4. A este formato se le llama notación de puntos.
Ahora tenemos tres tipos distintos de direcciones: primero, tenemos el nombre del nodo, quark, después tenemos las direcciones IP, y por fin están las direcciones hardware, como la dirección Ethernet de 6 bytes. De alguna forma todas ellas deben relacionarse, de modo que cuando escribamos rlogin quark, se le pueda pasar la dirección IP al software de red; y cuando el nivel IP envíe datos a la Ethernet del Departmento de Físicas, de algún modo tiene que encontrar a qué dirección Ethernet corresponde la dirección IP. Lo cual no resuta trivial.
Estos pasos para encontrar las direcciones IP se llaman resolución de nombres, para mapear nombres de nodo con direcciones IP, y resolución de direcciones para hacer corresponder estas últimas con direcciones hardware.
4.5.2 IP en lineas serie, SLIP
Para lineas serie se usa frecuentemente el estandar “de facto” conocido como SLIP o Serial Line IP (IP sobre linea serie). Una modificacion del SLIP es el CSLIP, o SLIP Comprimido, que realiza compresion de las cabeceras IP para aprovechar el bajo ancho de banda que proporcionan los enlaces serie. Un protocolo serie distinto es el PPP, o Point-to-Point Protocol (Protocolo Punto a Punto). PPP dispone de muchas mas caracteristicas que SLIP, incluyendo una fase de negociacion del enlace. Su principal ventaja sobre SLIP es, sin embargo, que no se limita a transportar datagramas IP, sino que se diseñó para permitir la transmision de cualquier tipo de datagramas.
4.5.3 EL protocolo de control de transmisión, TCP
Pero la historia no se acaba con el envio de datagramas de un nodo a otro. Si deseamos acceder a quark, necesitamos disponer de una conexion fiable entre su proceso rlogin en erdos y el proceso de shell en quark. Para ello, la informacion enviada en uno y otro sentido debe dividirse en paquetes en el origen, y ser reensamblada en un flujo de caracteres por el receptor. Esto que parece trivial, implica varias tareas complejas.
Una cosa importante a saber sobre IP es que, por si solo, no es fiable. Supongamos que diez personas de nuestro Ethernet comienzan a transferirse la última versión de XFree86 del servidor de FTP de GMU. La cantidad de tráfico generada por esto podría ser excesiva para que la maneje la pasarela, porque es demasiado lenta, y anda escasa de memoria. Si en ese momento enviamos un paquete a quark, sophus podría tener agotado el espacio del buffer durante un instante y por tanto no sería capaz de reenviarlo. IP resuelve este problema simplemente descartándolo. El paquete se pierde irrevocablemente, lo cual traslada la responsabilidad de comprobar la integridad y exactitud de los datos a los nodos extremos, y su retransmision en caso de error.
De esto se encarga otro protocolo, TCP, o Transmission Control Protocol (Protocolo de Control de la Transmision), que construye un servicio fiable por encima de IP. La propiedad esencial de TCP es que usa IP para darnos la impresion de una conexión simple entre los procesos en nuestro equipo y la máquina remota, de modo que tenemos que preocuparnos de como y sobre que ruta viajan realmente nuestros datos. Una conexión TCP funciona basicamente como una tubería de doble sentido en la que ambos procesos pueden escribir y leer; podemos imaginarla como una conversacion telefonica.
TCP identifica los extremos de tal conexión por las direcciones IP de los dos nodos implicados, y el número de los llamados puertos de cada nodo. Los puertos se pueden ver como puntos de enganche para conexiones de red. Si vamos a explotar el ejemplo del teléfono un poco más, uno puede comparar las direcciones IP con los prefijos de área (los números representarían ciudades), y los números de puerto con los códigos locales (números que representan teléfonos de personas concretas).
Mediante rlogin, la aplicación cliente (rlogin) abre un puerto en erdos, y se conecta al puerto 513 de quark, en el que se sabe que está escuchando el servidor rlogind. Esto establece una conexión TCP. Usando esta conexión, rlogind realiza el procedimiento de autorización, y entonces muestra la shell. La entrada y salida estándar de la shell se redirigen a la conexión TCP, de modo que cualquier cosa que escribamos a rlogin en nuestra máquina será pasado a traves del canal TCP y entregado a la shell como entrada estandar.
4.5.4 Protocolo de mensajes de control de internet (ICMP)
El protocolo de mensajes de control de Internet o ICMP, lo usa el software de gestión de red para comunicar mensajes de error entre nodos. Por ejemplo, si estamos en la maquina erdos y hacemos un telnet al puerto 12345 del nodo quark y no hay procesos escuchando en ese puerto, recibirá un mensaje ICMP de “puerto inalcanzable”.
Hay mas mensajes ICMP, muchos de ellos referidos a condiciones de error. Sin embargo, hay uno interesante que es el de redirección. Lo genera el módulo de encaminamiento al detectar que otro nodo está usándolo como pasarela, a pesar de existir una ruta mucho más corta. Por ejemplo, tras configurarse la tabla de encaminamiento de sophus, esta puede estar incompleta, conteniendo rutas a través del encaminador por defecto gcc1. Por lo tanto, los paquetes enviados inicialmente a quark irán por gcc1 en lugar de niels. En este caso gcc1 notificará a sophus que está usando una ruta costosa y reenviará el datagrama a niels, al mismo tiempo que devolverá un mensaje ICMP de redirección a sophus informándole de la nueva ruta.
Pero aprece un nuevo problema, pues la redirección de ICMP y el protocolo RIP no incluyen mecanismos de verificación de la autenticidad de los mensajes. Esto permite a los piratas corromper el tráfico de la red mediante mensajes ICMP. Por ello, algunas versiones del código de Linux tratan los mensajes de redirección que afectan a rutas de red como si fueran redirecciones de rutas a nodos.
4.5.5 La libreria de Sockets
En sistemas operativos UNIX, el software que realiza todas las tareas y protocolos descritos anteriormente es generalmente parte del kernel, y por tanto también del de Linux. El interface de programación más común en el mundo UNIX es la Librería de Sockets de Berkeley, Berkeley Socket Library. Su nombre proviene de una analogía popular que ve los puertos como enchufes, y conectarse a un puerto como enchufarse. Proporciona la llamada bind para especificar un nodo remoto, un protocolo de transporte, y un servicio al que un programa pueda conectarse o escuchar (usando connect, listen, y accept). La librería de sockets, sin embargo, es algo más general, ya que proporciona no sólo una clase de sockets basados en TCP/IP (los sockets AF_INET), sino también una clase que maneja conexiones locales a la máquina (la clase AF_UNIX). Algunas implementaciones pueden manejar también otras clases.
En Linux, la librería de sockets es parte de la librería C estándar libc. Actualmente soporta los sockets AF_INET y AF_UNIX, pero se hacen esfuerzos para incorporar el soporte de los protocolos de red de Novell, de modo que se añadirían eventualmente una o más clases de sockets.
4.6 HISTORIA DE LAS REDES CON LINUX
Siendo el resultado del esfuerzo concentrado de programadores de todo el mundo, Linux no habría sido posible sin la red global. Así que no sorprende que ya en los primeros pasos del desarrollo, varias personas comenzaran a trabajar para dotarlo de capacidades de red. Casi desde el principio existía ya una implementación de UUCP para Linux; y fue en el otoño de 1992 cuando se comenzó a desarrollar el soporte de TCP/IP, cuando Ross Biro y otros crearon lo que ahora se conoce como Net-1.
Después de que Ross dejara el desarrollo activo en Mayo de 1993, Fred van Kempen comenzó a trabajar en una nueva implementación, reescribiendo gran parte del código. Este esfuerzo continuado se conoce como Net-2. En el verano de 1992 salió la primera versión pública de Net-2d (como parte del kernel 0.99.10), y ha sido mantenida y ampliada por varias personas, muy especialmente por Alan Cox, dando lugar al Net-2Debugged. Tras una dura corrección y numerosas mejoras en el código, cambió su nombre a Net-3 después de que saliese Linux 1.0. Esta es la versión del código de red que se incluye actualmente en las versiones oficiales del kernel.
Net-3 ofrece controladores de dispositivo para una amplia variedad de tarjetas Ethernet, así como SLIP (para enviar tráfico de red sobre líneas serie), y PLIP (para líneas paralelo). Con Net-3, Linux tiene una implementación de TCP/IP que se comporta muy bien en entornos de red de área local, mostrándose superior a algunos de los Unix comerciales para PCs. El desarrollo se mueve actualmente hacia la estabilidad necesaria para su funcionamiento fiable en nodos de Internet.
Además de estas facilidades, hay varios proyectos en marcha que mejoraran la versatilidad de Linux. Un controlador para PPP (el protocolo punto a punto, otra forma de enviar tráfico de red sobre líneas serie) esta empezando a tener gran auge. Alan Cox también ha implementado un controlador para el protocolo IPX de Novell, pero el esfuerzo para un paquete de red completo compatible con el de Novell se ha paralizado por el momento, debido a la negativa de Novell a facilitar la documentación necesaria. Otro proyecto con gran éxito es samba, un servidor de NetBIOS gratis para Unix, escrito por Andrew Tridgell.
Otra implementación más de red TCP/IP es la realizada por Matthias Urlichs, quien escribió un controlador de RDSI para Linux y FreeBSD. Para ello, integró algo del código de red de BSD en el kernel de Linux.
Sin embargo, Net-3 acabaría por llegar para quedarse (aunque en la ctualidad se está sustituyendo por Net-4). Alan es también el autor de una implementación del protocolo AX.25 usado por radioaficionados.
Sin duda, la modularización, aun desarrollándose para el kernel, traerá también nuevos impulsos al código de red. Los módulos nos permiten añadir controladores al kernel en tiempo de ejecución.
Aunque todas estas diferentes implementaciones de red intentan dar el mismo servicio, hay grandes diferencias entre ellas a nivel de kernel y dispositivos. Además, no podremos configurar un sistema con un kernel Net-2e con utilidades de Net-2d o Net-3, y viceversa. Esto sólo se aplica a comandos que tienen mucho que ver con el funcionamiento interno del kernel; las aplicaciones y los comandos de red comunes como rlogin o telnet se ejecutan en cualquiera de ellos.
4.7 SEGURIDAD DEL SISTEMA
Un aspecto muy importante de la administración de sistemas en un entorno de red es proteger al sistema y a sus usuarios de intrusos. Los sistemas administrados sin ningún cuidado ofrecen muchos huecos a los malintencionados: los ataques van desde averiguar las claves hasta acceder a nivel de Ethernet, y el daño causado puede ser desde mensajes de correo falsos hasta perdida de datos o violación de la privacidad de los usuarios.
La seguridad del sistema comienza con una buena administracion del mismo. Esto incluye comprobar la propiedad y permisos de todos los ficheros y directorios vitales, monitorizar el uso de cuentas privilegiadas, etc. También es conveniente usar un sistema de claves que fuerce ciertas reglas en las claves de los usuarios que las hagan difíciles de adivinar. El sistema de claves ocultas (shadow password), por ejemplo, requiere que una clave tenga al menos cinco letras, y contienen tanto mayúsculas como minúsculas y números.
4.8 EL SISTEMA DE NOMBRES DNS
4.8.1 Resolucion de nombres
El direccionamiento en TCP/IP se basa en numeros de 32 bits. Esos números no son fáciles de recordar, mientras que sí lo es el nombre que se le asigna a cada máquina, como gauss o strange. Existe una aplicación que es capaz de traducir nombres a direcciones IP, y es conocida como sistema de resolucion de nombres o DNS.
Una aplicación que desee encontrar la dirección IP correspondiente a una máquina de la que conoce su nombre, no tiene que incluir rutinas para ello, ya que en las librerías estándares (libc) existen ya rutinas preparadas, como gethostbyname o gethostbyaddr.
En otros sistemas se encuentran en otras librerías distintas de la libc pero esto no sucede en Linux. Al conjunto de rutinas que hacen estas tareas se les conoce como “sistema de resolución”.
En una red pequeña no es difícil mantener una tabla /etc/hosts en cada máquina, y modificarla al agregar, eliminar o modificar nodos. Pero resulta complicado cuando hay muchas máquinas ya que, en principio, cada una necesita una copia de /etc/hosts.
Una solución a esto es compartir esta y otras bases de datos con el NIS, o Sistema de Informacion de Red, desarrollado por Sun Microsystems y conocido también como páginas amarillas. En este caso, las bases de datos como la de /etc/hosts se mantienen en un servidor NIS central y los clientes accederán a ellas de forma transparente al usuario. En todo caso, esta solución sólo es aconsejable para redes pequeñas o medianas, ya que implican mantener un fichero central /etc/hosts que puede crecer mucho, y luego distribuirlo entre los servidores NIS.
En Internet, se comenzo almacenando la informacion en un fichero similar al hosts, mantenido por el NIC, y obtenido regularmente por los demas servidores. Cuando la red creció comenzaron los problemas de sobrecarga de servidores, ademas de que el NIC tenía que ocuparse de todos los nombres de los nodos de Internet, y evitar la duplicidad de los mismos.
Por esto, en 1984 se diseñó y adoptó oficialmente un nuevo sistema, el DNS o sistema de nombres por dominios, diseñado por Paul Mockapetris.
4.8.2 Introducción al DNS
DNS organiza los nombres de los nodos en una jerarquía de dominios. Un dominio es una colección de nodos relacionados de alguna manera, como estar en la misma red o pertenecer a una misma organizacion o pais. Por ejemplo, las universidades norteamericanas se agrupan en el dominio edu, y cada universidad mantiene un subdominio dentro de edu. Nuestro ejemplo, la Universidad de Groucho Marx, mantendría el dominio gmu.edu y las máquinas del Departamento de Matematicas se encontrarían dentro del dominio maths.gmu.edu. De este modo el nombre completo de la máquina erdos será erdos.maths.gmu.edu. El nombre completo se conoce como nombre totalmente cualificado o FQDN, e identifica a ese nodo en todo el mundo.
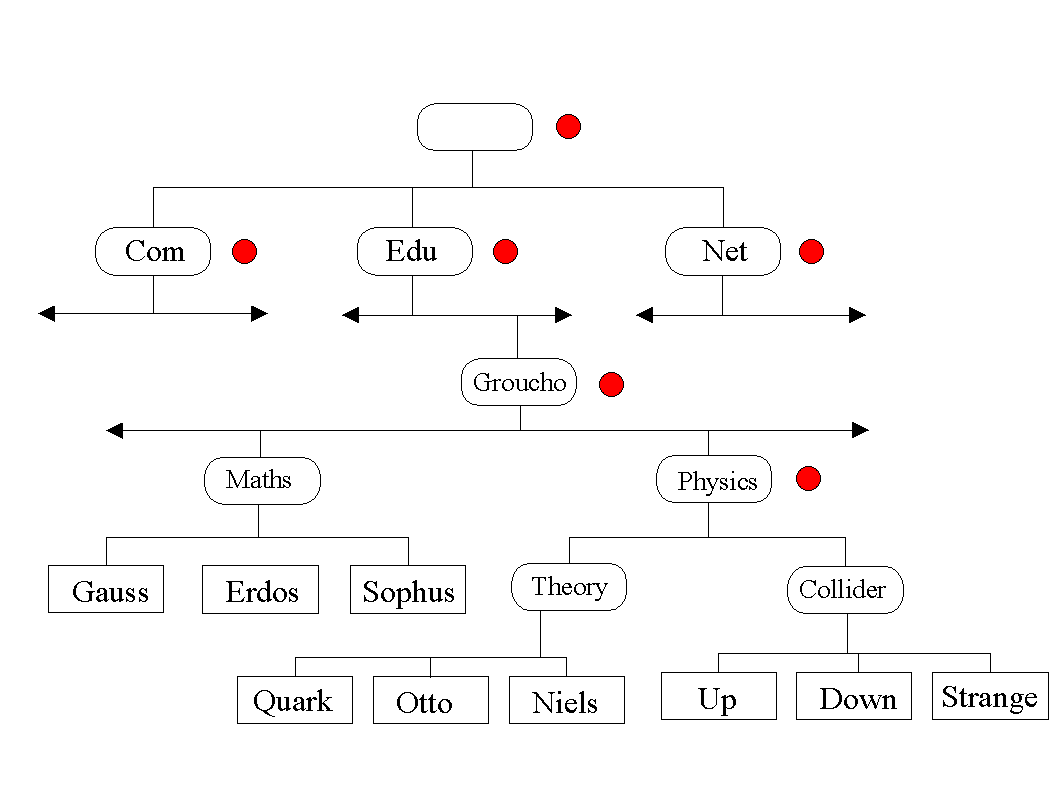 Figura 6 – Organización de dominios
Figura 6 – Organización de dominios
Aquí se muestra una sección del espacio de dominios. La entrada de la raíz del árbol, que se indica con un punto rojo, se puede denominar dominio raíz, y agrupa al resto de los dominios. Para indicar que un nodo se expresa en notación FQDN, se puede terminar el nombre en un punto, indicando así que el nombre incluye al del dominio raíz. (Figura 6)
Dependiendo de su localización en la jerarquía, un dominio puede ser de primer, segundo o tercer nivel. Pueden existir otros niveles pero no son frecuentes. Por ejemplo, algunos dominios de primer nivel muy usuales son los siguientes:
| Dominio | Descripción |
|---|---|
| edu | Aquí se incluyen casi todas las universidades o centros de investigación norteamericanos. |
| com | Compañías u organizaciones con fines comerciales. |
| org | Organizaciones no comerciales. Las redes UUCP privadas se encuentran aquí. |
| net | Pasarelas y otros nodos administrativos de la red. |
| mil | Nodos militares norteamericanos. |
| gov | Nodos del gobierno norteamericano. |
| uucp | Oficialmente, todos los nombres de nodos UUCP sin dominio han sido movidos a este nuevo dominio, .uucp. |
En general, los dominios anteriores pertenecen a redes norteamericanas. Algo especialmente cierto con los dominios mil o gov.
Fuera de los Estados Unidos, existe un dominio de primer nivel para cada país, de dos letras segun se define en la norma ISO-3166. Finlandia, por ejemplo, usa el dominio fi; el dominio de corresponde a Alemania y el dominio es corresponde a España. Cada país organiza por debajo del primer nivel, los dominios de segundo nivel, de manera parecida a los americanos en algunos casos (por ejemplo, con dominios com.au o edu.au) o directamente por organizaciones, como sucede en España (con dominios como uji.es para la “Universitat Jaume I”).
Por supuesto, un nodo dentro del dominio de un país puede no estar fisicamente en él. El dominio únicamente identifica al nodo como registrado en el NIC de ese país. Así, un comerciante español puede tener una delegacion en Australia, y tener sus nodos australianos registrados dentro del dominio de primer nivel español, es.
Esta organización por dominios soluciona el problema de la unicidad de nombres. Además, los nombres totalmente cualificados no son díficiles de recordar.
Pero DNS tiene otras ventajas: permite delegar la autoridad sobre un determinado subdominio a sus administradores. Por ejemplo, los subdominios maths y physics de la UGM son creados y mantenidos por el Centro de Calculo de dicha universidad. Y si el mantenimiento del subdominio maths.gmu.edu fuese complicado (por número elevado de nodos, existencia de subdominios internos, etc), el Centro de Calculo de la UGM puede delegar la autoridad sobre ese subdominio al departamento de Matemáticas. La delegación de un subdominio implica el control total del mismo por parte de la organización en la que se delegó, con total libertad para crear nuevos subdominios internos, asociar nombres a nodos, etc.
Para este fin, el espacio de nombres se divide en zonas, cada una asociada a un dominio. Notese que existe una diferencia entre zona y dominio: el dominio groucho.edu incluye todos los nodos de la UGM, mientras que la zona groucho.edu incluye sólo los nodos que mantiene directamente el Centro de Cálculo, ya que los nodos del subdominio physics.groucho.edu pertenecen a la zona controlada por el Departamento de Físicas. En la imagen anterior marcamos el inicio de una zona con un pequeño circulo a la derecha del nombre del dominio.
Este apartado de redes está extraido del libro “Linux Network Administrator Guide” [Kirch99], donde se hace una detallada exposición del funcionamiento y configuración de las redes bajo entorno Linux. Aunque la versión original es en inglés es posible encontrar en Internet una traducción al castellano.
5 EL SISTEMA X-WINDOW
5.1 ¿Qué es X-window?
El sistema X-Window, (X-window o simplemente las X) se trata de la herramienta de software para el desarrollo de interfaces gráficas de usuario (GUI’s) para estaciones de trabajo. Una GUI es en pocas palabras una interfaz usuario / computadora que se ejecuta en modo gráfico. X-window para linux y para todos los sistemas más basados es UNIX lo que MS Windows es para los sistemas basados en DOS. Con una gran diferencia, que X-Window es un estándar para los sistemas de ventanas basados en UNIX. Esta estandarización supone que cualquier interfaz GUI puede ser ejecutada en cualquier computadora e incluso en varias a la vez. Más información en [SHV+93].
5.2 Historia y necesidad
En 1984, Laboratory for Computer and Science del Instituto Tecnológico de Massachussets (MIT) en Cambridge, Massachussets, inicio el poyecto Athena que fue liderado por Robert Schefler y Jim Gettys. En el MIT como en muchas más organizaciones había muchos, terminales, sistemas operativos, CPUs etc. lo que dificultaba una tarea estandarizada. El proyecto Athena tenía una meta muy definida, que era que todos los programas pudieran estar interactivamente disponibles para todos los usuarios en cualquier estación de trabajo del MIT. El inicio de este sistema fue el sistema de ventanas de la Stanford University que se llamo W.
La primera versión disponible para los diseñadores estuvo en el año 1986, y la versión fue la Versión 10 Revisión 4. Grandes empresas del tamaño de IBM, SUN, HP, Digital etc. han participado desde el principio en el desarrollo de este sistema. Desde su aparición hace ahora catorce años se ha ido actualizando continuamente, la última versión existente es la Versión 11 Revisión 6.3 (X11R6). Más información en [SHV+93].
5.3 Arquitectura Cliente / Servidor
En linux el proceso gráfico no es más que otro proceso que ejecuta el sistema operativo. Esto evita muchos problemas de estabilidad al kernel. Otra ventaja que tiene es la absoluta independencia del sistema operativo y el entorno gráfico. En contrapartida a todas estas ventajas, existe el inconveniente que el entorno gráfico reduce su velocidad en comparación a otros sistemas gráficos. Estos últimos incluyen los procesos referentes al subapartado gráfico en el propio núcleo. Ver figura 1. Aunque esta práctica tiene la ventaja de que el sistema gráfico es más veloz. Se hace un gasto innecesario de recursos, aun sin usar ninguna aplicación, y estar más propensos a fallos del sistema debidos a errores en el apartado gráfico.
Toda la filosofía de X Window se basa en la arquitectura cliente/servidor. Esta arquitectura es el modelo de sistema X mediante la cual los clientes, programas de aplicaciones, se comunican con los servidores que controlan parte del hardware.
El programa que habilita un entorno gráfico X-window en un ordenador es el servidor X (X server). Se le llama servidor ya que este programa sólo se dedica a escribir en pantalla lineas, cuadros y funciones gráficas básica. El servidor X ofrece funciones gráficas primarias a las aplicaciones (clientes) que las soliciten y este las muestra en pantalla. El servidor es el programa encargado de gestionar un display. Un display se debe entender como la unidad formada por la o las pantallas y por los dispositivos de entrada, bien sea un ratón, un teclado, un trackball etc. todo este conjunto es un display. Un servidor puede servir a varios clientes a la vez. La otra parte de la arquitectura cliente / servidor es el cliente, básicamente es una aplicación que se esta ejecutando en modo gráfico. El servidor es la unidad de visualización, que puede a su vez estar formada por varios monitores o pantallas físicas.
El servidor se encarga de captar las entradas del usuario y se las pasa a las aplicaciones o clientes X, dicha información proviene de los dispositivos de entrada del display, para que los clientes actúen en consecuencia. Los clientes tienen que captar esta información y operar. La respuesta del cliente es mandada al servidor ordenándole que dibuje dicha respuesta en la pantalla o las pantallas del display. Descodifican los mensajes de los clientes, como las peticiones de información o el movimiento de una ventana. Toda la comunicación entre el cliente y el servidor se realiza en lenguaje formal X window.
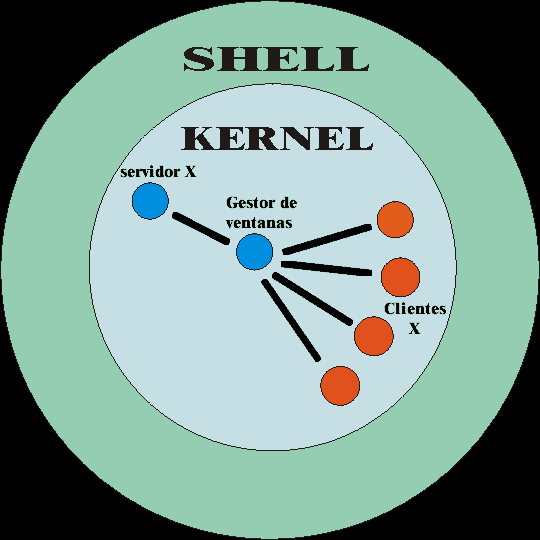
Todo esta arquitectura se debe a que el sistema X windows tiene una gran flexibilidad de uso en redes. La conexión del Servidor X a los clientes no esta limitada a la misma máquina. Sino que cualquier aplicación o cliente que se este ejecutando en una red se puede conectar a cualquier servidor.Ver figura 2 Cuando decimos conectarse se quiere decir que se puede visualizar en el ordenador que ejecuta un servidor X. Una forma de aprovechar esta flexibilidad es utilizar desde casa un ordenador personal conectado a una gran computadora para aprovechar la potencia de esa computadora desde casa. Esta práctica de compartir aplicaciones esta muy extendida, de hecho existen un tipo de ordenadores cuya única función es ejecutar un servidor X, se denominan “terminales X”. Estos ordenadores en ocasiones no disponen de dispositivos de almacenamiento y no son muy potentes con lo que se consigue muchos puestos de trabajo a un precio muy reducido. Otro punto importante es que no existe ninguna razón por la que el sistema X window este restringido al sistema operativo Unix o Linux. De hecho existen servidores X para DOS, Windows Macintosh u OS/2.
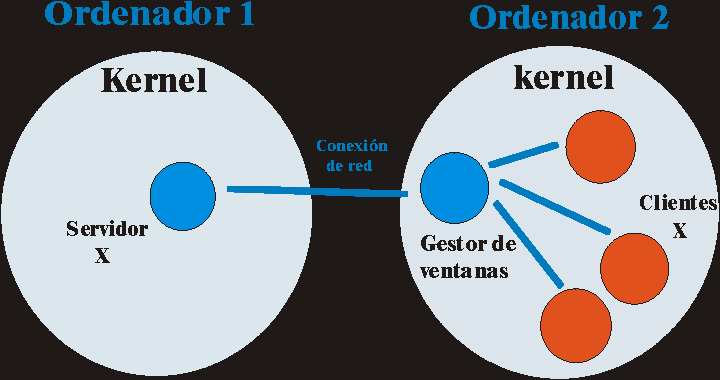
Para profundizar más en este aspecto puden consultar los libros de la bibliografía [SHV+93] y en [[MP98]
]65
Hay que señalar que la filosofía del sistema X-Window puede parecer engañosa ya que invierte la posición tradicional del cliente y el servidor. Tradicionalmente un servidor ha sido por ejemplo: la gran computadora que tenía los archivos que eran servidos a los clientes, o un servidor de conexión a internet a los que se conecta el usuario. En estos casos el servidor es una computadora remota, con grandes capacidades de procesamiento y almacenamiento que tenía muchas tareas cargadas, y los clientes son los usuarios. El sistema X-Window funciona al revés. El servidor es el usuario con su terminal X y el cliente esta corriendo en una computadora remota, o no, que suele tener grandes capacidades de calculo y almacenamiento y que suele estar cargada de clientes.
Una de las partes más importantes de la arquitectura cliente servidor es la conexión física entre el cliente y el servidor. De ello dependerá en gran medida el rendimiento del sistema. Una conexion de red rápida entre cliente y servidor o que el servidor este en la misma computadora que el cliente hará que el entorno funcione de una manera rápida.
La comunicación entre el cliente y el servidor sistema X-Window se realizan mediante el denominado protocolo X (X protocol). Este protocolo X permite definir el número exacto de bytes necesarios para definir una ventana. El problema es que la programación con este lenguaje es extremadamente complicada y laboriosa.
Se puede comparar el protocolo X al lenguaje máquina. De la misma manera que el ensamblador proporciona potencia a la programación en lenguaje máquina, las funciones Xlib proporcionan la potencia del protocolo X con un coste menor.
Xlib es un biblioteca de unas 300 funciones escritas en C que generan protocolo X, que facilitan la programación básica, las funciones Xlib son el punto de partida para aprender a manejar X Window y aunque sea imprescindible dominarlas. Para programar a más alto nivel nos harán falta otras herramientas.
Existen también las llamadas X Toolkit Intrinsics más comúnmente conocido como Xt intrinsics, son herramientas de más alto nivel ya que nos ayudaran a crear bloques de pantalla llamados widgets, como por ejemplo menús, barras de desplazamiento ,botones etc. La ventaja de esta herramienta es que da a la aplicación una apariencia estándar fácil de ver y de entender, con lo que se gana en facilidad de uso que es lo que se pretende desde el principio al usar el sistema X window. . Para más información se puede consultar en el libro de la bibliografía [SHV+93].
5.4 XFree86
La versión que linux utiliza del sistema X Window es XFree86. Esta es una versión gratuita de la distribución oficial de UNIX que funciona en procesadores compatibles con la tecnología x86 como (AMD,Ciryx o Intel).
Referente al hardware necesario para poder ejecutar el X-window. XFree86 soporta la mayoría de tarjetas que hay en el mercado. Las principales causas que dificultan el desarrollo de XFree86 para algunas tarjetas es que como se distribuye el código fuente, algunas empresas no están dispuestas a mostrar el funcionamiento de su tarjeta. Otra más común es que suele pasar un tiempo desde que sale un producto hasta que esta listo el desarrollo correspondiente. Ya que el código cuesta de escribir y de comprobar. En cuanto a memoria y procesador XFree86 corre en un simple intel 386 con al menos 16 MB de ram. Esta memoria puede ser 8 MB mínimo de principal y 8 MB de memoria virtual o de intercambio (SWAP).
5.5 Arranque del sistema X-Window
El inicio del sistema X window, implica que se ha de cargar tanto el servidor X como algunos clientes para poder empezar a utilizar el entorno gráfico. Hay un par de maneras principalmente de iniciar el X-window. Quizá la más usada sea mediante el guión de inicio llamadostarx.Que se ejecuta en cualquiera de las consolas en modo texto. Este programa no es más que un guión de comandos que ejecuta el Servidor X, inicializa algunos recursos para que serán utilizados por los clientes y también conecta al servidor algún cliente.
Otra manera de iniciar el servidor X es mediante el programa xdm ,o programa gestor de pantallas. Se trata de un programa muy potente que no sólo permite controlar la sesión X en el ordenador local, sino también en los terminales X y todos aquellos ordenadores que se conecten a través de la red. Esto ayuda a tener mayor seguridad en el acceso a la red. El servidor X tiene que interactuar con el hardware del sistema, con lo que tiene que tener privilegios de superusuario para poder funcionar. Esto es lo que ocurre al usar startx a causa de que por defecto se le otorgan unos permisos especiales. De este modo cualquiera puede ejecutar un servidor X, y como el servidor X puede tener bugs (errores), con los que un usuario con suficientes conocimientos podría “engañarle” para ejecutar programas con privilegios de root(administrador del sistema o superusuario).. Lo que hace el xdm concretamente es arrancar el servidor X y un rectángulo en el cual el usuario se ha de identificar ante la máquina y una vez el usuario se identifica mediante su nombre y contraseña se ejecutan los clientes que tenga personalizados el usuario en cuestión.
5.6 Gestores de ventanas
El gestor de ventanas es uno de las aplicaciones X más importantes, ya que se trata del programa que da el aspecto a todo el entorno gráfico y que controla todas las operaciones relativas al dibujo de ventanas. En linux un gestor de ventanas es un cliente más que está conectado al servidor X. Esto implica que el sistema en si, no esta ligado a ningún gestor de ventanas en particular. Con lo que se consigue una gran personalización del entorno gráfico. Esto tiene el inconveniente de que cambia totalmente la manera de de interpretar las pulsaciones del ratón o del teclado.
5.6.1 Fvwm y sus derivados
Fvwm es una de las familias de gestores de ventanas más usadas dentro de entornos Linux. Fvwm(Fine Virtual Window Manager) y todos sus derivados. son a su vez derivados del twm(tab window manager), que es el gestor que se distribuye con las versiones oficiales de X-window y por tanto con XFree86.
Una de las cualidades de twm es que tiene grandes posibilidad de personalizarse al gusto del usuario. Todo esto unido al hecho de que es un programa de libre distribución ha hecho de twm el ancestro de toda la familia de gestores fvwm
Fvwm fue desarrollado en un principio con la finalidad de reducir el uso de memoria que necesitaba el twm aunque fuese a costa de reducir su capacidad de personalización, darle un aspecto tridimensional y principalmente los escritorios virtuales. Los escritorios virtuales permiten simular un escritorio más grande de lo que cabe en la pantalla con lo que podemos tener ventanas en otros escritorios fuera de la pantalla e intercambiar ventanas entre ellos.
5.6.2 Otros gestores de ventanas
Existen también derivados de fvwm como son el fvwm95, fvwm2, afterstep etc. El más usado entre la comunidad linux es el afterStep. En un principio estaba ideado para emular el sistema operativo NEXTSTEP aunque debido a su atractivo diseño y sus posibilidades se ha ganado gran parte de los usuarios de Linux.
Existe una gran oferta de gestores de ventanas para linux, desde más derivados del twm como son ctwm o vtwm hasta otros que se han diseñado desde cero. También existen gestores de ventanas muy espectaculares que convierten el ordenador en un espectáculo multimedia. El principal gestor de ventanas es el enlightenment que llena la pantalla de atractivos colores y formas.
5.7 Gestores de escritorio
Un gran inconveniente de los gestores de ventanas es que las aplicaciones no tienen forma de comunicarse entre ellas ni de controlar el comportamiento del gestor de ventanas. Esto se subsana al pasar del gestor de ventanas al gestor de escritorio (Desktop manager). Este ultimo tiene las siguientes ventajas con respecto al gestor de ventanas:
- Provee de un aspecto uniforme a todas las aplicaciones gráficas, dotándolas de un interfaz de uso común.
- Podemos marcar un objeto con el ratón y arrastrarlo hasta cualquier aplicación y ver su contenido allí.
- Permite el acceso transparente a cualquier recurso, ya este en el disco o en otro lugar de la red.
- Distingue entre aplicaciones abiertas y enlaces a recursos.
- Ofrece un interfaz gráfico para configurar y personalizar todos los aspectos del entorno gráfico.
Aunque estas características son muy deseables por la mayoría de usuarios en Linux aún falta camino por recorrer, hasta poseer un entorno con todas estas características. Afortunadamente hay mucha gente trabajando en ello, y ya nos estamos acercando a sistema mejor. Se trata de KDE (K Desktop Environment). KDE provee de un entorno completo, panel de menús, un gestor de tareas, un escritorio orientado a objetos(iconos), un gestor de escritorio que permite ver archivos locales y en unidades de red y un gran sistema de ayuda.Para más información podemos visitar su web en http://www.kde.org
Otro poyecto similar que se esta desarrollando más recientemente es el GNOME. Tiene una gran similitud con el KDE. Debido al apoyo de RedHat y otras compañías este gestor de escritorio hace que tenga un futuro prometedor. De hecho ya es el principal rival del KDE.Para más informacion podemos visitar la página de GNOME en http://www.gnome.org. Hay más gestores de escritorio como el CDE (common desktop envirenment) que debido a su condición de programas comerciales no tienen el apoyo de la mayoría de usuarios.
Todo lo expuesto desde el apartado 5.4 se puede ampliar en el libro de la bibliografía: [MP98].
CONCLUSIÓN
Después de haber realizado este trabajo y haber visto la evolución de este sistema operativo, no dudamos en concluir que estamos ante un sistema operativo de futuro, abriéndose paso a través de otros sistemas comerciales, que, teóricamente, deberían ofrecer características mejores a las que ofrece Linux.
Nuestra opinión sobre este sistema operativo es que ha tenido esta gran evolución en los cuatro o cinco últimos años, en gran medida debido a la ideología que sigue este sistema operativo, la cual permite que cualquier usuario tenga la posibilidad de modificar el código fuente, personalizando el sistema, reparando los posibles “bugs” del sistema o creando programas nuevos a los que cualquiera pueda acceder, modificar y reparar a través de la red.
Dada esta característica, creemos que Linux tiene una gran perspectiva de futuro. Esto no queda únicamente así, sino que además, está produciendo una revolución en la actual concepción de mercado de software comercial, creando nuevos tipos de licencias con los que los programas puedan ser comerciales, pero incluyendo las fuentes, con lo que se consigue obtener unas características parecidas a la del software libre.
Además gracias al sistema multitarea y multiproceso de Linux, que ofrece una gran potencia de cálculo y velocidad de intercomunicación, este sistema es apto para grandes estaciones de trabajo y de servidores de red, entre otros.
Centrándonos más en el tema del trabajo, nuestra opinión, tanto teórica como práctica, es que es un sistema muy estable, apto y recomendable para cualquier informático, no solo con la gran cantidad de sistemas de ficheros y protocolos de red que es capaz de utilizar, sino que además ofrece una gran posibilidad de desarrollo, gran potencia en entorno gráfico, tanto desde el punto de vista de usuario como de programador, y una interfaz de red que permite la fácil comunicación entre sistemas UNIX, o cualuquier otro sistema operativo actual.
El único inconveniente que hemos encontrado a este sistema es que para un usuario de nivel bajo-medio, puede que sea un golpe un poco duro encontrarse con un sistema operativo por línea de comandos, con multitarea real, cosas poco usuales en el resto de sistemas que suelen emular la multitarea desde un entorno visual. Esto se está intentando mejorar, creando mejores programas de instalación y utilizando interfaces gráficas más intuitivas.
REFERENCIAS
| Referencia | Autores |
|---|---|
| [BBD+97] | Michael Beck, Harald Böhme, Mirko Dziadzka, Ulrich Kunitz, Robert Magnus y Dirk Verworner (1997). Linux Kernel Internals (Second Edition). Editorial: Addison-Wesley |
| [Kirch99] | Olaf Kirch (1999). Linux Network Aministrator Guide. Fuente: Proyecto LuCAS |
| [MP98] | César Martín Pérez e Ismael Pérez Crespo (1998). Linux. Editorial: Anaya Multimedia |
| [NR95] | Cameron Newhan y Bill Rosenblatt (1995). Learning the Bash Shell. Editorial: O’Reilly & Associates, Inc. |
| [Rusling98] | David A Rusling (david.rusling@digital.com) (Enero 1998). El núcleo de Linux. Fuente: http://www.hispalinux.org |
| [SHV+93] | Antonio Vaquero Sánchez, Raymundo Hugo Rangel, Gerardo Quiroz Vieyra, Willy Vega Gálvez y Luis Ernesto Ramírez (1993). Aplique X Window. Editorial: McGraw-Hill/Interamericana de España, S.A. |